
If I ask about microservices, how should Your Excellency respond?
Catalog
- Introduction
- why microservices are needed
- Service Discovery
- Inter-Service Communication
- Microservice Splitting
1. Introduction
1.1 The Status of Microservices
In the current Internet world, no matter whether you are doing 2B-end [for enterprises] or 2C-end [for individual users] products, microservices development has blossomed everywhere, and most of the monolithic structure of the system only exists in the traditional software and medium-to-large-scale state-owned enterprise architectures.
But do you really understand microservices?

Let’s take a look at the requirements for microservices in a backend development engineer job JD:
**Candidates need to be proficient in the use of microservices frameworks, deeply understand the principles and operation mechanisms of microservices, and have unique insights into service splitting, inter-service calls, and service governance. **
Is it feeling cloudy or half-understood? It’s okay, we’ll get it after reading this article 😉
1.2 What are Microservices
There are many definitions of microservices, the official one is as follows:
Microservices are an architectural and organizational approach to developing software that consists of small, independent services communicating through well-defined APIs that are handled by small, independent teams. Microservices architecture makes applications easier to scale and faster to develop, thereby accelerating innovation and reducing time to market for new features.
In layman’s terms, microservices are an architectural pattern, or an architectural style. It advocates the division of a single application into a number of smaller services, each of which is managed independently, with services and services cooperating and coordinating with each other, ultimately providing users with a rapidly iterative go-live product.
For example, an e-commerce system may contain micro-services such as users, commodities, warehousing, orders, payments, and points systems:

Today we will talk about microservices in detail and the knowledge related to microservices interview. I believe that after reading this article, no matter whether you are dealing with an interview with a big internet company or a state-owned foreign enterprise, microservices are earned when asked 💰
2. Why we need microservices
2.1 The problem with monolithic architectures
In the beginning, when there were no microservices, applications in the Internet world used a monolithic architecture, i.e., all the modules under the system were put into a single service.

Often, these services are as small as a few, or as large as dozens of modules, and teams of dozens of people work together to develop them. At this time, the problems of monolithic architecture are gradually exposed:
- systems are usually accessed by APIs, and the tight coupling makes it difficult to maintain and expand;
- each business area needs to use the same technology stack, it is difficult to quickly apply new technologies, such as using Java or PHP;
- System modifications must be deployed/upgraded together with the whole system, which makes operation and maintenance complex and error-prone;
- When the system load increases, it is difficult to scale horizontally;
- If there is a problem in one part of the system, it may affect the whole system and cause collateral problems.
Thus, in 2012, the concept of microservices was proposed as a way to accelerate the development of Web and mobile applications, and began to attract much attention.
Time came to 2015, more and more Internet communities, forums, and Internet giants began to use microservices, and from 2018, more and more small and medium-sized enterprises also began to upgrade their microservices architecture.
Today, in 2023, according to a recent market research report, 95% of the applications in the market have been developed using microservices architecture.
2.2 Disadvantages of Microservices
1) High code complexity
Microservices interact with each other via HTTP, RPC, etc. Compared with the API form of monolithic architecture, it is necessary to take into account the failure of the called party, overloading, loss of messages, etc., and the code logic is more complex.
Transactional operations between microservices need to solve the problem of distributed transactions, and may need to introduce two-stage, best-effort notification and other ideas to solve the problem.
When there are a few functions (or database fields) overlapping between microservices, but they cannot be extracted into microservices, it is usually necessary to repeat the development, or do data redundancy, which increases the development and maintenance costs.
2) Heavy operation and maintenance tasks
At the time of launch, there may be service coupling relationships that require sequential and orderly service deployment. The most common situation is that A service calls the interface of B service, i.e., A depends on B. When you go online, you have to upgrade the B system first and then the A system.
Moreover, since the system is independent, a well-designed monitoring system is needed to monitor the operation status of each microservice. The purpose of real-time monitoring is to prevent modules in the business system from dropping out temporarily, which affects the overall business utilization.
3) Impact on performance
Compared to the monolithic architecture, the delay of REST and RPC communication between microservices is higher, especially when the call chain is long.
Moreover, when the business chain is long, it is more difficult to troubleshoot problems, and if multiple services are involved in the BUG, troubleshooting will be more complicated.
2.2 Characteristics & Principles of Microservices
Although microservices have disadvantages that do not exist in monolithic architectures, its advantageous characteristics of allowing high cohesion and low coupling of functional modules are enough for us to endure these to embrace it. In addition to this, microservices have the following characteristics:
1) Single responsibility
Generally, microservices are divided according to business logic, and each microservice is only responsible for the functions belonging to its own business domain, with clear logic and high module cohesion. For example, the user system, product system, order system, payment system, etc. mentioned above, each module has its own business characteristics.
2) Autonomy
Microservices are independent entities that can be deployed and upgraded alone, and each microservice communicates with each other through standard interfaces in the form of REST/RPC. And microservices can be realized with different technology stacks, and other modules are not affected.
Most commonly, many algorithm modules are implemented in Python, and the background business is implemented in Go or Java When the background module needs to call the interface of the algorithm module, as long as the protocol of the API interface is defined, the API call can be made in a friendly way.
Through isolation, meltdown and other techniques to ensure that a microservice exception does not affect other modules, which is also a microservice autonomy of the bottom of the pocket strategy.
3) Scalable
With business growth, a module can be expanded horizontally or vertically to facilitate elastic scaling and gray-scale release.
In different business scenarios, the pressure of different modules is inconsistent, for example, the e-commerce system under the limited-time spike business: the commodity system and the storage system will bear most of the traffic pressure, while the payment system may be more relaxed.
In order to cope with similar scenarios, we can distribute the modules of the merchandise system and the storage system to multiple machine deployments, and equally distribute the traffic pressure to different business machines to alleviate the high concurrency pressure of the modules.
4) Flexible Combination
Under the microservice architecture, functional reuse can be achieved by combining existing microservices. Although this can also be realized under the monolithic architecture, different combinations may make the interactions between monolithic architecture modules more and more complex, and ultimately make the system chaotic.
3. Service Discovery
3.1 Service Governance
As applications evolve from monolithic architectures to microservices, the demand for service governance such as service discovery, load balancing, and fusion-limiting between microservices increases significantly due to the substantial growth in the number of fine-grained microservice applications.
In a microservice scenario, each service has multiple instances, and a mechanism is needed to resolve the requested service name to the corresponding service instance address, which requires service discovery and load balancing mechanisms.
3.2 Service Discovery
Service discovery consists of two parts:
- Service registration: each service name sends information about the service instance to the registry and provides a heartbeat mechanism to ensure that the service is online;
- Service discovery: get the list of instances corresponding to the service from the registry.
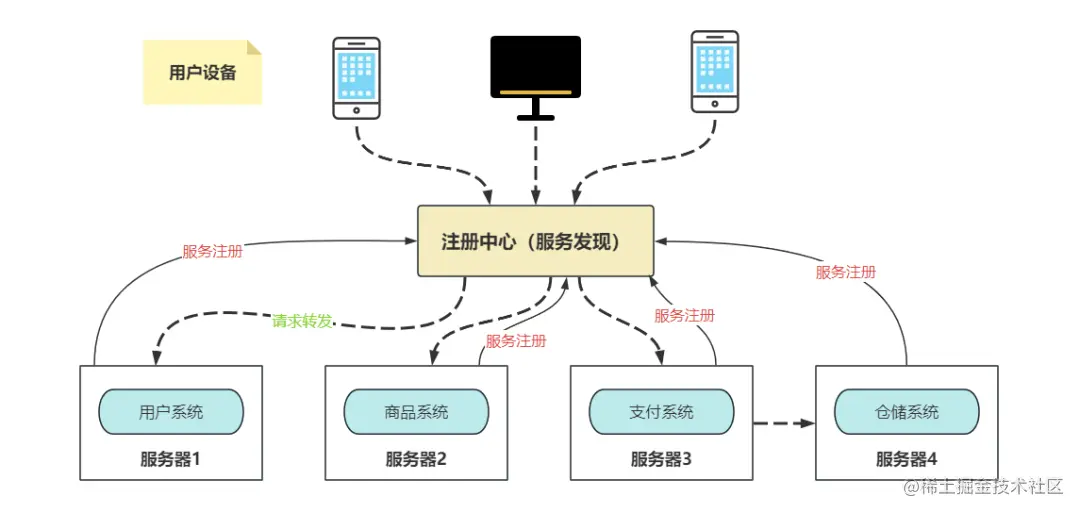
3 common strategies for service discovery:
- ETCD as a registry, each service module registers the service name and instance information to ETCD, and keeps its own lease unexpired to maintain the service online;
- Redis as the registry, each module maintains a timer and sends instance information and time to the registry module periodically, and the registry module derives the maximum timeout time based on the heartbeat time and network fluctuation time. If a module does not send the heartbeat message packet to the registry for a long time, it will be kicked out of the service cluster;
- Istio service registration and discovery is accomplished by the control plane Pilot and the data plane Envoy, the Pilot obtains service resource information such as service and endpoint through the K8s APIServer interface, and converts it into xDS messages to be sent to the Envoy component in the data plane, and the Envoy selects a service instance to be requested according to the load balancing policy configured when it receives the request. When the Envoy receives the request, it selects a service instance to forward the request according to the configured load balancing policy.
3.3. Load Balancing
1) What is load balancing?
Load balancing is generally used in conjunction with service discovery to select one of the service discovery parsed instances to initiate a request, and this process uses a load balancing policy.

As shown in the figure above, when the business deploys 4 commodity system services, when the request arrives at the registration center, **the registration center will hit the request to different servers **according to different load balancing algorithms to ensure that the load on each machine is not too high to affect performance.
2) Load Balancing Algorithm
Compare balanced forwarding to a teacher handing out candy, where the teacher is the registry and the students are the servers. Load balancing algorithm is a way for the teacher to give out candy to the students, neither letting the students starve nor giving candy to only one student [it’s not good to have too much blood sugar].
1, polling method
Assigns requests to back-end servers in sequential rotation, equalizing each back-end server, doesn’t care about the number of connections to the server or the current system load.
Using the analogy of a teacher handing out candy, the polling method is to hand out candy to students one by one, student 1, student 2, student 3 …… The rain falls evenly, and each student gets an almost equal number of candies.
2, randomized method
Randomly select a machine to visit, by the probability statistics know, When the number of calls, the more its allocation calls closer to the average, that is, the result of polling.
Using the analogy of a teacher handing out candy, the random method is that the teacher draws lots to decide who to give the candy to each time before handing it out, and each student gets an indeterminate number of candies. But probabilistically, when there are a lot of requests, the result is close to the average, similar to rolling dice, or tossing a coin.
3, weighted polling method
According to the hardware configuration and load of the server, the machine with high performance and low load is given a higher weight, making the machine with high weight more accessible.
When the number of requests is large, the ratio of the number of requests handled by each service converges to the ratio of weights.
Using the analogy of a teacher handing out candy, the weighted polling method looks at the teacher’s preferences for handing out candy, where the weights can be thought of as the student’s score. The teacher might give 3 candies to students who score 90 or more, 2 candies to students who score 75 or more, 1 candy to students who score 60 or more, and no candy to students who fail.
The ratio of the number of candies each student receives is based on the weights, so when the number of requests is higher, the ratio of the number of candies each student receives to the weights is closer.
4, source address hashing method
Get the IP address of the client and access a particular server by hash taking the mode. When the list of back-end servers and the hash algorithm are unchanged, the same client is mapped to the same server for each request.
To use the analogy of a teacher handing out candy, the source address hash method means that the teacher hands out candies of the same origin or brand to one student at a time, e.g., Heijirou candies are given to student 1, Shanghaojia candies are given to student 2, and so on. …… The number of candies each student gets depends on the number of candies of the corresponding brand.
Translated with www.DeepL.com/Translator (free version)
4. Inter-service calls
We have already introduced the characteristics of microservices above: ** Microservices interact with each other through HTTP, RPC, etc. **.
HTTP (HyperText Transfer Protocol) and RPC (Remote Procedure Call), the former is a protocol and the latter is a method, both of which are commonly used for service invocation.
RPC works on top of the TCP protocol (or HTTP), while HTTP works on top of the HTTP protocol, which is based on the TCP transport layer protocol, so RPC is naturally lighter and more efficient than HTTP.
4.1 HTTP
1) Introduction
HTTP service development, i.e. developing RESTful style service interfaces, is a common means of communication for information transfer when there are few interfaces and little interaction between systems.
2) Advantages
The advantages of HTTP interfaces are simple, direct, easy to develop, and can be transported using the ready-made HTTP protocol. When developing a service, it is necessary to agree on an interface document that strictly defines the inputs and outputs and specifies the request methods and parameters of the interface.
4.2 RPC
1) Introduction
**First of all, we need to know what is RPC? **
RPC (Remote Procedure Call) is a computer communication protocol. The protocol allows a program running on one computer to call a subroutine in another address space (usually a computer on an open network), and the programmer calls it as if it were a local program, without having to additionally program for this interaction (no need to pay attention to the details). –Wikipedia
A lot of non-specialists must have been confused when they saw this big explanation, as I was at first. It’s not hard to understand RPC, we just need to know that it’s a communication protocol, i.e. a format or convention that both parties need to follow.
2) Characteristics
Some people may still wonder: since they are both communication protocols, should we choose HTTP (HyperText Transfer Protocol) or RPC for program interaction and application development?
This starts from the difference of their properties, which are mainly considered from the following 4 points:
transfer protocol
- RPC is a communication protocol based on the TCP transport layer or the HTTP2 application layer;
- HTTP is based on HTTP protocol only, including HTTP1.x (i.e. HTTP1.0, 1.1) and HTTP2, and many browsers currently use 1.x by default to access server data.
Performance Consumption (from data type comparison)
- RPC, can be based on gRPC (a RPC framework) to achieve efficient binary transmission;
- HTTP, mostly implemented via json, where byte size and serialization consume more performance than gRPC.
load balancing
- RPC, basically comes with a load balancing strategy;
- HTTP, need to configure Nginx, HAProxy to realize.
Transport Efficiency
- RPC, use customized TCP protocol, can make the request message size smaller, or use HTTP2 protocol, can also be very good to reduce the size of the message, improve the transmission efficiency;
- HTTP, if it is based on HTTP1.x protocol, the request will contain a lot of useless content; if it is based on HTTP2.0, then a simple encapsulation can be used as RPC, which is when the standard RPC framework has more advantages of service governance.
3) Popular RPC Frameworks
- gRPC: based on the HTTP2.0 protocol, the underlying use of the Netty framework;
- Thrift: cross-language service development framework, through the code generator to save a series of basic development work;
- Dubbo: protocol and serialization framework can be plugged and unplugged.
Translated with www.DeepL.com/Translator (free version)
4.3 Differences between HTTP and RPC
In summary, we can easily find that RPC is stronger than HTTP in terms of performance consumption and transmission efficiency, as well as load balancing. At this point, careful friends may have found, then why our common systems and websites are using the HTTP protocol, not changed to RPC communication?
To give a common example, HTTP is like Mandarin, RPC is like a local dialect, such as Cantonese, southwest of Yunnan, Guizhou, Sichuan.
The advantage of speaking Mandarin is that everyone understands it, and most people speak it, so HTTP has a certain universality. Speaking dialect, the advantage is that it can be more concise, more confidential, more customizable, the disadvantage is that the other party who “speaks” the dialect (especially the client side) must also understand, and once everyone speaks a dialect, it is difficult to change the dialect.
So RPC is generally used for internal service calls, such as between service A and service B in Alibaba’s Taobao system.
The concept of microservices emphasizes more on independence, autonomy and flexibility, but RPC has more restrictions. Therefore ** microservice frameworks generally use HTTP RESTful calls, except for systems with high efficiency requirements **.
5. Service Splitting
Through the above description, we must have familiarized ourselves with the basic features of microservices from several levels of microservice introduction, service governance, service discovery and inter-service communication.
** Then as an architect/intermediate and advanced programmer, how do we go about distinguishing the boundary issues of each module and how to split microservices? **
Next, we introduce three common ways to split microservices.
5.1 Business Domain
Splitting microservices by business domain (also called pendant splitting), such as user, mall, order business modules, if there is the same functionality needs to be aggregated, it is carried out to sink to a separate microservice, unified call.
The benefits of splitting microservices by business are, high cohesion and no easy coupling between businesses.
5.2 Functional Positioning
Split microservices by functional positioning (also called horizontal splitting), such as login and registration, user shopping, and points redemption. If the same module is used by more than one function, you can further split the microservices and call them uniformly.
The benefits of splitting microservices by function localization are: ** high development efficiency, more independent testing and use of different functions**.
For users, when using a certain type of system function, they often call the API of the same microservice, which can better avoid collateral problems and distributed transaction problems.
5.3 Level of Importance
Split microservices according to the degree of importance, distinguishing between core and non-core modules, e.g.: e-commerce system inside the order module core, logistics module non-core. The key points to distinguish whether a module is core or not are:
- Is it indispensable. Such as the e-commerce system, the user’s most concerned about the function of online shopping, orders is to save the user’s shopping records of the core business, naturally, is very important.
- High user attention, i.e., high traffic, can bring exposure for the system. For such a module (e.g., e-commerce display module), it will greatly affect the user’s judgment of the overall product quality, which is also extremely important.
In addition, the industry on the topic of microservice splitting has a relatively well-established system design methodology, such as the famous DDD (Domain-driven design) .
Its principle is to establish domain model through event storm, reasonably divide domain logical and physical boundaries, establish domain object and service matrix and service architecture diagram, define code structure model that conforms to the idea of DDD layered architecture, and ensure the consistency of business model and code model.
Due to personal understanding and the limited length of the article, I will not expand on the discussion here. If you want to understand the friends move a small hand point a concern, the follow-up time can be arranged.
Translated with www.DeepL.com/Translator (free version)