
Machine Learning from Data Labeling
Table of Contents
- Machine learning
- Labeling systems
- Number of system tasks
- Flow of system tasks
- Summary
1. Machine Learning
1.1 What is machine learning?
As the name suggests, the ability and insights of a computer program or system to learn by itself without direct human help or intervention, so that it can answer questions for humans. In layman’s terms, it is the process of creating an Artificial Intelligence (or AI for short) model that learns on its own like a human being, allowing for rapid advancement of knowledge in a particular area.
The difference is that the AI only needs a short period of self-learning to reach or even exceed the human level. For example, AlphaGo only learned Go for 9 days before it could beat a Korean 9-dan player with a 99% win rate, so it is undoubtedly a god of learning.
1.2 Artificial Intelligence is not intelligent
Although AI’s learning ability is very strong, in the eyes of human beings, it is at the level of a god of learning.
What’s interesting is that most outsiders, including me, have been unaware for a long time of the fact that AI itself is not intelligent, e.g., machine learning, which often relies on low-paid crowdsourced workers to manually annotate and fine-tune the data so that they can continue to learn.
And I happen to be working on big model-related data labeling lately, so I’ll share with you some of the labeling-related points I’ve recently combed through.
1.3 What is Data Labeling
Data annotation is the process of attributing, labeling, or classifying data to help machine learning algorithms understand and categorize the information they need to process. This process is critical in model training for AI, allowing AI to accurately understand various data types such as images, audio files, video clips, or text.
The current decision-making AI (e.g., Shake or Taobao’s recommendation system, Tesla’s Smart Driving, etc.), generative AI (e.g., OpenAI’s ChatGPT, Baidu’s Wenxin Yiyin, etc.) can’t be separated from the annotation step, and all of them currently rely on a large number of annotators, or are screened by human beings after being annotated by machines.
Here to share a text annotation GitHub annotation project.
2. The annotation system
This annotation system is called Open Assistant, a project that aims to make chat-based language macromodeling accessible to everyone.
This project has been open sourced on GitHub, ⭐️ has broken 32k in just a few months, for those interested: [github.com/LAION-AI/Op…]
On this annotation system, several processes of machine learning can be simulated, including conversation tree expansion, session annotation and final scoring, and then filtering out the conversations with the highest scores to continue learning.
2.1 Conversation tree
In the annotation system, the conversation tree is the most basic data structure, which simulates the conversation process of machine learning, and its structure is as follows:
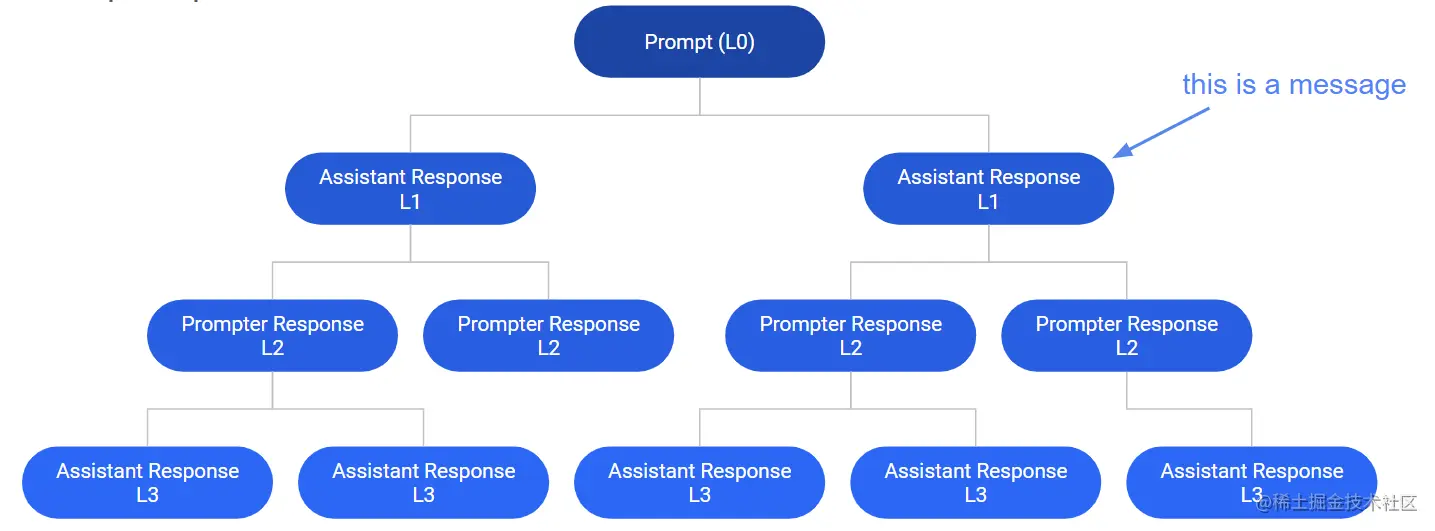
First, the root node of the tree is the Initial Instruction, which is the first sentence given by a user (Prompt), which may be a prompt, or may throw out a question.
Second, then Chatbot gives a reply, chatbot based on different processing dimensions, including their own level of knowledge, summarization ability, etc., will give a reply to the user’s question (Assistant Response).
Third, when the chatbot gives a reply, ** the user continues to ask ** (Prompt Response), at this time the dialog tree has come and gone.
Then the chatbot gives a response (Assistant Response), continuing to expand the dialog tree.
When a node in the tree, or the user, no longer responds, the tree ends. However, these chatbots will continue to learn from all the generated dialog trees, i.e., all the conversations with all the users, in order to become smarter and give better answers during the conversations.
2.2 Tasks
In addition to the dialog tree, Task is also a very important data structure in the annotation system. The update of the dialog tree and its nodes is accomplished through one different task. Tasks in the annotation system are of the following types:
- Initialization prompt (initial_prompt) task: the system requires the user’s identity to create an initial instruction, this initial instruction may be to seek an explanation of the concept, a problem of algebraic operations, or the creation of the article type of requirements, that is, ** the user asked a question; **
label_initial_prompt: let the labeler to label the initial instruction, when more than one person labeling is completed, start by the chatbot to reply to the initial prompt, that is, ** let the labeler to screen out unhealthy questions, such as illegal and criminal, politically sensitive questions; ** ** the chatbot reply to the initial prompt, that is, ** the user asked a question; ** the user asked a question; ** the user asked a question; ** the user asked a question; ** the user asked a question; ** the user asked a question
** Chatbot reply (assistant_reply): replying to the initial instruction with a trained chatbot can be seen as the first question answer, at the second level of the dialog tree. ** This step is used by different AIs to reply to the user’s question according to their knowledge level; ** - Labeling the chatbot’s reply (label_assistant_reply): the content of the chatbot’s reply to the user’s instructions/replies is labeled, and the labeled qualified replies are ready to proceed to the next round of the conversation or to the sorting task (enough people are labeled qualified). ** labeling personnel to screen and score the AI’s responses, and ultimately select the AI with the best responses to continue training (can be interpreted as raising compulsion, eliminating unqualified ones); **
- Reply as a user (prompter_reply): reply to the chatbot’s message as a user, corresponding to the dialog tree will add a node, that is, ** by the user to continue to ask questions **;
- Label the user’s reply (label_prompter_reply): label the content of the user’s reply to the chatbot, and the next round of dialog can be carried out after the labeling passes, ** label the user’s questions, and screen out unhealthy and meaningless information **;
** Sorting users’ replies (rank_prompter_replies): when many users have replied, each user’s annotation result is qualified, at this time ** the annotator sorts the text quality of users’ replies and selects some optimal replies for the bot to learn; ** - Ranking the replies of chatbots (rank_assistant_replies): similarly, through ** sorting scoring, the optimal replies among chatbots are selected for the models of other bots to proceed to learning and training; **
** Random tasks: the system randomly selects more than one task for the annotators to complete.
3. The number of system tasks
The state flow of the conversation tree and its node expansion is accomplished by one different task. Since the number of session trees in different states is inconsistent, the number of different types of tasks displayed on the page is also inconsistent.
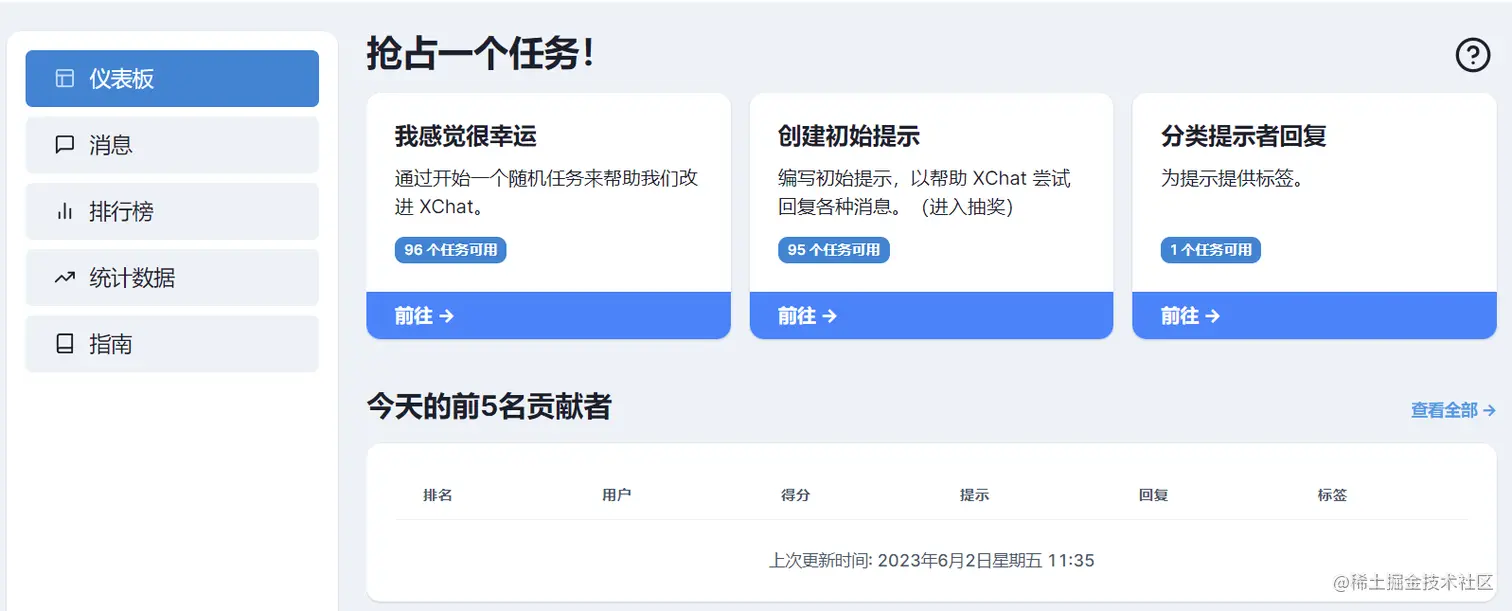
1) Number of random tasks (random)
The number of random tasks (shown on the page as “I feel lucky”, this is a system bug, don’t worry) is the total number of all task types, when you choose to do a random task, the system will randomly select a session tree and execute the corresponding task.
2) Number of tasks to write commands as a user (initial_prompt)
In order to minimize write conflicts when updating data tables, the system will limit the number of active conversation trees, and the number of conversation trees that can currently remain active is the number of tasks to write instructions as a user.
This number is controlled by a combination of two indicators:
- Metric 1 is the number of dialog trees remaining to be created, plus the number of dialog trees that have already been created and can continue to grow;
- Metric 2 is the number of dialog trees currently available for queuing;
Finally, the number of tasks writing instructions as a user takes the smaller of the two metrics.
** In simple terms, this number is the number of questions the user can and does ask. **
3) Number of tasks labeled user initial instructions (label_initial_prompt)
The dialog tree needs to be labeled with the user’s initial instructions after they have been written by the user. Therefore, the number of tasks for labeling the user’s initial instructions is the number of dialog trees that are currently active, have a status of initial waiting to be labeled (initial_prompt_review), and have a user’s number of labels that is lower than the configured value.
When multiple users have completed labeling a dialog tree and the labeling results are satisfactory. The state of the dialog tree changes to growing, and the number of tasks labeled with the user’s initial instruction is reduced by one.
** In a nutshell, this number is the total number of initial questions that can be annotated by the annotator. ** ***
4) Number of tasks to reply as a chatbot (assistant_reply)
When 3) has finished annotating the user’s initial instructions and needs to reply to the session tree, it will first reply as an assistant. Therefore, the number of tasks replied to as a chatbot is the number of conversation trees that are currently active, growing, and created with the role of prompter.
**This is the total number of labeled questions that the AI can reply to (of course, in the system, a human user can also simulate the AI). ** ** This is the total number of questions that the AI can reply to.
5) Number of tasks labeled for chatbot replies (label_assistant_reply)
Once 4) replies to the conversation tree as a chatbot, these replies need to be labeled. Therefore, the number of tasks to label chatbot replies is the number of conversation trees that are currently active, with a conversation tree state that is growing (GROWING) and below the configured value. These conversation tree leaf nodes are created with the role of chatbot (assistant).
** In a nutshell, this quantity is the total number of annotated AI replies that are available to the annotator. **
6) Number of tasks replying as a user (prompter_reply)
After 5) has finished labeling the chatbot’s replies, if the labeling result is qualified, it needs to continue to reply to the session tree, and here it will reply as a user.
Therefore, the number of tasks replying as a user is the number of active, growing conversation trees whose leaf nodes were created with the role of chatbot (assistant).
7) Number of tasks to label the user’s replies (label_prompter_reply)
After 6) replies to the conversation tree as a user, these replies need to continue to be labeled.
Therefore, the number of tasks labeled user replies is the number of conversation trees that are currently active, with a conversation tree state that is growing (growing) and below the configured value, and for which the creation role of the leaf node of the conversation tree is the user (prompter).
8) Number of tasks to rank chatbot/user replies (rank_assistant_replies/rank_prompter_replies)
When the annotation is completed, if the number of nodes (both root and leaf nodes) in the conversation tree reaches the target value, the status of the conversation tree is set to ranking.
Therefore, the number of tasks to be ranked is the number of conversation trees that are currently active and have the status of being ranked. There are two types of ranking tasks:
- if the leaf node of the dialog tree is a user reply, then the user’s reply is ranked;
- sorting the replies of the chatbot if the leaf node of the dialog tree is a chatbot reply.
4. Labeling system task flow
1) Writing commands as a user
Before writing a command as a user, some basic checks are done, such as user authentication, whether the number of queued tasks for the user in the recent period exceeds the limit value, and whether the remaining number of creation of the dialog tree is sufficient.
If one of the basic checks fails, the process is terminated; otherwise, the initial instruction writing starts.
When the user completes the task of writing the initial instruction, the details of the initial instruction (e.g., text, user name, role-prompter, time, etc.) are stored in the database as a new dialog message and a new dialog tree is generated, which is now in the state of initialization prompt (initial_prompt_review).
2) Labeling initial user commands
After the dialog tree is created, the user’s initial instructions need to be labeled.
Before labeling, it is necessary to do some basic checks, such as user authentication, whether the number of queued tasks of the user in the recent period exceeds the limit, and whether the number of remaining tasks for labeling the user’s initial instruction is sufficient.
If one of the basic checks does not pass, then report an error and return; otherwise, start labeling the user’s initial instructions.
Then from inside the conversation tree randomly select a conversation tree that needs to be labeled with initial instructions (prompts_need_review), and label the sentences of the initial prompts for scoring.
The dimensions for labeling are commonly:
- Whether it is spam;
- Not Chinese, inappropriate, contains PII, hate speech, or contains sexual content;
Scoring dimensions are:
- high quality, level of creativity, level of humor, level of politeness, level of violence
When the annotation is submitted, the system will save the annotation results of each user, and store the annotation results in different tables according to the specifics of the annotation [e.g., whether to report or not, whether to like or not, etc.].
Next, it will determine whether the number of times the dialog tree has labeled the user’s initial instruction reaches the configured value, and if a certain number of labeling times has been reached, it will start to rate the sub-node of initial instruction.
Note: the current scoring is only based on whether it is spam or not, and the language is not clear (not Chinese) to calculate the score.
Score calculation method: suppose the initial instruction of the dialog tree has been labeled by 3 users, 1 of them labeled it as spam, and the other 2 users labeled it as not spam, the ratio of labeling as spam is 1/3. Similarly, if 1 user labeled the initial instruction as language-unintelligible, and the other 2 users didn’t label it as language-unintelligible, the ratio of labeling as language-unintelligible is 1/3. The total score of labeling is 0.34 (1/1), the total score of labeling is 0.34 (1/1), the total score of labeling is 0.34 (1/1). The total marking score is 0.34 (1-1/3-1/3).
In the end, when the labeling score exceeds the configured value (default 0.6), the labeling result of the root node is set as qualified and stored in the table to start the next step, otherwise, it is set as unqualified, and the dialog tree is set to the state of aborted_low_grade, and will not be continued in the subsequent process.
3) Replying as a chatbot
After the initial command is labeled, the dialog tree turns into a growing state, at which time the dialog tree can be replied by the chatbot.
Before replying to the initial command as a chatbot, some basic checks are done, such as user authentication, whether the number of queued tasks of the user in the recent period exceeds the limit, and whether the remaining number of replies in the dialog tree is sufficient.
If one of the basic checks fails, the process is terminated; otherwise, a conversation tree that has been labeled initial instruction completion and is in a growing state is randomly selected for replying.
When the chatbot replies to a task, the details of the reply (e.g., text, username, role-assistant, time, etc.) are stored in the database table as a new dialog message, and the current chatbot’s reply task is updated to done.
4) Labeling chatbot replies
After the chatbot replies to the initial command, it needs to annotate the reply.
Before labeling, some basic checks should be done, such as user authentication, whether the number of queued tasks for the user in the recent period exceeds the limit, and whether the number of remaining tasks for labeling the chatbot’s replies is sufficient.
If one of the basic checks is not passed, an error is reported and returned; otherwise, from inside the conversation tree randomly select a conversation tree that needs to be marked for chatbot replies (reply_need_review), and start marking chatbot replies.
In addition to the same marking dimensions as the marking initial instruction, the marking dimensions for marking chatbot replies are increased:
- As a response to the prompt task, is it a bad response?
Scoring dimensions added:
- How helpful was it?
When the annotation is submitted, the system saves the annotation results for each user and stores the annotation results in a different table according to the specifics of the annotation [e.g., whether it is reported or not, whether it is liked or not, etc.].
Next, it determines whether the number of times the conversation tree has labeled the user’s initial instruction has reached the configured value, and if a certain number of labeling times has been reached, it starts to rate the sub-node of bot replies.
Note: Like labeling the initial instruction, the current scoring is only based on whether it is spam or not, and the language is not clear (not Chinese).
Eventually, when the labeling score exceeds the configured value (default 0.6), the labeling result of the root node is set as qualified and stored in the table to start the next step, otherwise, it is set as unqualified, and the conversation tree is set as aborted_low_grade, and will not continue to go through the subsequent process.
When the labeling is completed, determine whether the number of nodes in the current conversation tree has reached a certain number, and if the target value is reached, the state of the conversation tree will be set to the sorting (ranking) state.
5) Replying as a user
After the bot replies have been labeled, the dialog tree continues to grow, and then replies as user are used to expand the child nodes.
Before expanding the tree as a user, some basic checks are done, such as user authentication, whether the number of queued tasks of the user in the recent period exceeds the limit, and whether the remaining number of replies in the tree is sufficient.
If one of the basic checks fails, the process is terminated; otherwise, a bot replying to a conversation tree that has been labeled complete and is in a growing state will be randomly selected for replying.
When the chatbot replies to a task, it stores the details of the reply (e.g., text, username, role-assistant, time, etc.) as a new dialog message in the database table and updates the current user’s reply task as done.
6) Labeling user replies
After the user has replied to the dialog tree, it is necessary to continue to label the user’s replies.
Before labeling, it is also necessary to do some basic checks, such as user authentication, whether the number of queued tasks of the user in the recent period exceeds the limit, and whether the number of remaining tasks for labeling the user’s replies is sufficient, etc. If one of the basic checks is not passed, an error is reported.
If one of the basic checks does not pass, an error is reported; otherwise, from the conversation tree randomly select a conversation tree that needs to be labeled with the user’s reply (reply_need_review), and start labeling the user’s reply text.
As with the labeling initial command, the marking dimensions for labeling user replies are:
- Whether it is spam or not;
- is not Chinese, inappropriate, contains PII, hate speech, or contains sexual content;
The scoring dimensions are:
- quality, creativity, humor, politeness, violence.
When the annotation is submitted, the system will save the annotation results of each user, and according to the specifics of the annotation [e.g., whether to report or not, whether to like, etc.] the annotation results will be stored in different tables.
Next, determine whether the number of times the dialog tree annotated user replies reaches the configured value, and if a certain number of annotations has been reached, start scoring the sub-node of user replies.
Note: Like the annotation initialization command, the current scoring only calculates the score based on whether it is spam or not, and the language is not clear (not Chinese).
Eventually, when the labeling score exceeds the configured value (default 0.6), the labeling result of the root node is set to qualified and stored in the table to start the next step, otherwise it is set to unqualified, and the conversation tree is set to aborted_low_grade, and no longer continue to go through the subsequent process.
When the labeling is completed, determine whether the number of nodes in the current conversation tree has reached a certain number, if it reaches the target value, then the state of the conversation tree will be set to the ranking state; otherwise, the conversation tree will continue to grow, and the cycle of steps 3) to 6).
7) Ranking chatbot replies
After completing the task of 4) labeling the chatbot’s replies, we need to sort the chatbot’s replies if the conversation tree enters the sorting state.
Before sorting, some basic checks will be done, such as user authentication, whether the number of queued tasks for the user in the recent period exceeds the limit value, and whether the number of remaining tasks for sorting chatbot replies is sufficient.
If one of the basic checks fails, an error is reported and returned; otherwise, a conversation tree waiting for chatbot replies to sort (incomplete_rankings) is randomly selected from inside the conversation tree to start sorting tasks.
Sorting involves ranking the correctness and validity of multiple replies from the chatbot.
When the sorting results are submitted, the system saves the sorting results for each user and records the sorting operation in the log table by adding 1 to the number of sorted messages for the sorted message node.
When the number of sorted chatbot replies for a conversation tree node exceeds the configured value, scoring ranking starts for the sorting of that conversation tree, and the state of the conversation tree at this time is the ready_for_scoring state (ready_for_scoring).
After sorting by the algorithm, the ranking of chatbot replies of the sub-nodes of the dialog tree is calculated, and if the scoring process is completed successfully, the dialog tree is changed to the ready_for_export state; otherwise, if there is an error in the scoring process, the dialog tree will be set to the scoring_failed state.
5. Summary
In addition to text annotation, we also come across image, audio, and video annotation during AI model training, which is done by a large number of annotation employees. However, as AI and GPT grow well, and large models bloom both at home and abroad, the labeling may be left to robots in the future, and the labeling will slowly become smarter and more automated.
According to market research, the current application of AI in the entertainment media field is dominated by content distribution, and there are some auxiliary applications in the content production stage, and in the later stage, it will move towards massive auxiliary content creation or even massive replacement of human creation.
- Machine-assisted human stage: generative AI greatly reduces the cost and threshold of content production, reduces costs and increases efficiency for content companies, and existing large model companies are expected to obtain higher profits;
- Machine “replacement” stage: users only need to input instructions to get the required content created by AI, the importance of the content distribution link decreases, the existing Internet entertainment giants face the challenge of “accurately providing content that meets user needs” to “providing content production tools that meet user needs”.
To put it in human terms, now these AIs are tools for us to keep our rice bowls, but in the future, they may be tools for us to steal our rice bowls!