In the field of computer science, distributed systems are a challenging research area and an essential optimization practice for Internet applications, while CAP theory and BASE theory are two key concepts in distributed systems.

2. What is a distributed system
First, let’s talk about distributed systems. You can think of a distributed system as a large network of computers, consisting of multiple computer or server nodes, which may be located in different geographical locations.

As shown in the figure, the three nodes of the application layer are published in different cities. These nodes can communicate and collaborate with each other to accomplish complex tasks.
Imagine you are a team leader with a task to accomplish. If you complete it alone, it may take a long time.
But if you break the task down into several subtasks and assign them to your team members, they can work in parallel and complete the task faster. This is the core idea of distributed systems.
3 CAP Theory
Next, let’s talk about CAP theory, which is a very important principle in the design of distributed systems.
CAP refers to the three basic principles of Consistency, Availability, and Partition tolerance in distributed systems.
C - Consistency
Consistency means that no matter which node of the distributed system you read from, you get the same copy of the data and it ensures the accuracy of the data.
In distributed systems, there are three broad types of consistency which are Strong Consistency, Weak Consistency and Final Consistency.
Strong Consistency
Strong consistency requires that when a user accesses data in a distributed system, the data should be exactly the same regardless of the response from any node.
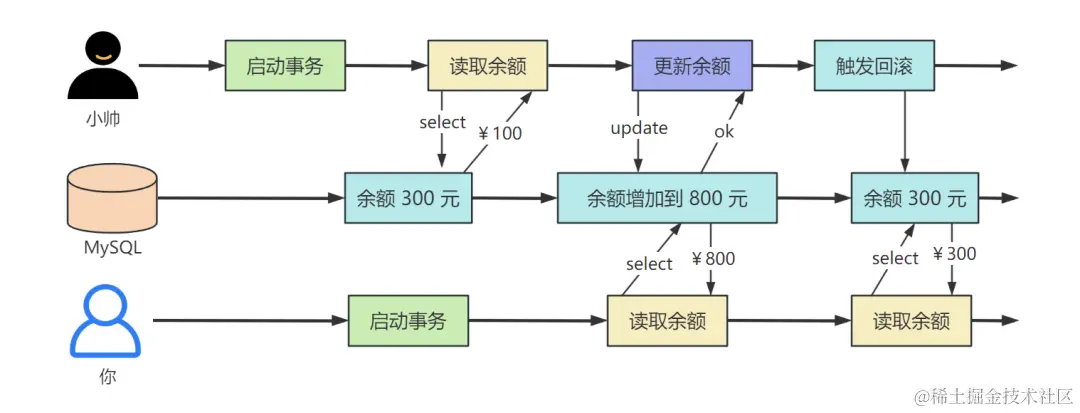
For example, there are 10 pairs of sneakers left in the inventory in the order system, Zhang San just bought a pair of sneakers, after the data update is completed, the next number of sneakers seen by Li Si is only 9 pairs, otherwise there may be overselling.
However, this requires more time and effort to coordinate, just like when Li Si is buying shoes, he must queue up and wait for Zhang San’s purchase action to finish first before he can continue, which is less efficient.
Weak Consistency
Weak consistency means that after the data in a distributed system has been updated, it is also allowed to allow subsequent accesses to get the old data before the update.
It is like going to a party where everyone has their own clock. The time of each clock may be a little different, but that doesn’t stop everyone from getting together and having fun.
Weak consistency improves the efficiency of the business, but sometimes it can lead to some confusion; imagine the long wait if the party-goers’ clocks are too far off.
Final Consistency
Final consistency is a special form of weak consistency that requires that the system’s data update is complete, and after a period of time, all subsequent accesses get the latest data.
It’s like message propagation in the circle of friends. When you send a message, it is not immediately seen by all your friends, but eventually, everyone will see the same message.
The vast majority of general business systems use final consistency as the design philosophy for distributed systems based on cost-effective considerations.

Consistency in CAP theory, on the other hand, requires strong consistency. As described in the official documentation: All nodes see the same data at the same time.
A - Availability
Availability means that every request of a distributed system should be responded to and should be completed within a limited time.
Availability ensures the stability and reliability of the system, and it describes the ability of the system to serve the user well, without user actions failing or access timing out, which affects the user experience.
It is the official term Reads and writes always succeed, the service is always available within the normal response time.
P - Partition Tolerance
Partition Tolerance means that the system can continue to run in case of network partition or communication failure, that is, if the network communication between nodes fails, or one of the nodes in the system has a problem, we still need to ensure that the business system is available.
That is, The system continues to operate despite arbitrary message loss or failure of part of the system, the distributed system is still able to externally provide services that satisfy consistency or availability in the event of a node or network partition failure.
4. Characteristics of CAP
4.1 Importance of partition fault tolerance
At this point, students with a basic knowledge of distributed computing may ask, “CAP theory is indeed very important, but it seems that these three characteristics cannot be satisfied at the same time,” right?
Yes, this is the core idea of CAP theory.
CAP theory tells us that in a distributed system, we can only satisfy at most two of the characteristics at the same time, but not all three at the same time.

Why can’t C, A, and P be both? First of all, we have to know that in a distributed system, due to the unreliability of the network, in order to ensure that the service can always be provided to the outside world, so ** partition fault tolerance must be guaranteed **.
Imagine if there is only one partition, talk about distributed is meaningless. And more than one partition, there must be partition failure problems, distributed systems to ensure partition fault tolerance has become the most basic claim.
So now we only need to consider whether we can satisfy both consistency and availability on the basis of partition fault tolerance, which we can prove by using the counterfactual method.
4.2 AP Or CP
Suppose we now have two partitions, P1 and P2, with the same data, D1 and D2, on the partitions, which are now identical.

Next, a request 1 accesses P1 and changes the data on D1. Then another request 2 accesses P2 to access the same data on D2.
At this point, we need to make a tradeoff.
Ensure consistency first
If we first guarantee to satisfy consistency and partition fault tolerance, i.e. CP.
This process can easily occur: D1 has updated the data, but when querying D2, the data is returned as old.
In order to ensure that D2 and D1 data are completely consistent, you must lock the D2 data on P2 when updating the D1 data, and then synchronize the D2 update after the D1 update is complete.
In this process, the locked D2 will not be able to give a real-time response to request 2, that is, violating the availability of P2.
Therefore, under the premise of consistency, CAP can not be satisfied at the same time.
Guarantee availability first
If availability and partition fault tolerance are guaranteed to be met first, that is, AP.
Availability requires that both P1 and P2 can respond in real time, so when D2 has just finished updating and has not yet been synchronized to D1, the data in the two DBs is inconsistent, which violates the data consistency on P1 and P2.
Therefore, under the premise of availability, CAP cannot be satisfied at the same time.
4.3 CAP tradeoffs

CAP You can’t have all three, so what should you choose? Generally according to our business we can have the following choices.
Satisfy consistency and partition fault tolerance CP
Guarantees strong consistency of partitioning (C) and does not require availability (A).
It is equivalent to waiting for the data to be fully synchronized before the request arrives at a certain system before getting the data response from the system. Generally, this model is used in financial systems where the data needs to be strictly consistent.
Meet Availability and Partition Fault Tolerance AP
Availability of partitions is guaranteed (A) and strong consistency is not required (C).
When requesting access to data in a partition, you may get old data that is not synchronized. This model generally only requires that the data meets the final consistency, which in turn ensures system response speed and high availability.
AP is widely used in the industry, such as the famous BASE theory (discussed in detail below).
Satisfying Availability and Consistency AC
As mentioned above, it is not possible to guarantee both strong consistency (C) and availability (A) of a system in a distributed system.
This is because partitioning in a distributed system is objectively unavoidable, whereas databases in a monolithic system can guarantee data consistency and availability through transactions, such as the four main characteristics of transactions (Atomicity, Consistency, Isolation, and Durability, or ACID for short) in MySQL.
5. BASE Theory
The BASE theory summarizes the practice of distributed systems on the Internet today. Its core idea is that since the cost of achieving strong consistency in a distributed system is too high, it is better to settle for the second best.

It is only necessary for each application partition to ensure data consistency to the best of its ability on the basis of providing highly available services, that is, to ensure the final consistency of the data.
BASE theory is the CAP to ensure partition fault tolerance (P) under the premise of availability (A) and consistency (C) of the trade-offs, which consists of Basically Available (Basic Available), Soft State (Soft State), Eventually-Consistent (Final Consistency) three aspects of the composition, referred to as the BASE Theory.
In distributed systems, CAP theory provides a theoretical framework, while BASE theory provides a guiding principle for practical operation.
5.1 Basic Availability
BASE theory recognizes that a distributed system may choose to reduce performance or consistency requirements in order to maintain basic availability in the face of failures or anomalies.
This means that the system may experience some transient inconsistencies, but will eventually reach a consistent state.

Just as a system design for a banking system generally has functional and non-functional requirements, we first need to ensure basic usability of the core functional requirements.
Functional Requirements
In a banking system, transaction modules such as user withdrawals, transfers, etc. are the core functions, which are the basic needs of users and cannot go wrong.
The non-core functions can be abnormal, but need to be guaranteed to be fixed within a period of time.
Non-functional requirements
Non-functional requirements refer to other requirements that user’s business does not depend on, such as performance-related: users are required to transfer money within 0.5 seconds, but due to network delays and other reasons, the response can be delayed to 1~2 seconds.
Due to such anomalies in the system, thus affecting the high availability of the system, but the core process is still available, i.e. basic availability.
5.2 Soft State
Soft state means that system services may be in an intermediate state, and data may be delayed in synchronization in the process of ensuring consistency, but it will not affect the availability of the system.
For example, after we have finished paying for a train ticket, we may be in an intermediate waiting state that is neither fully successful nor failed. The user has to wait for the system’s data to be fully synchronized before getting the final status of whether or not the ticket was purchased successfully.
BASE theory recognizes that in a distributed system, the state may soften over time rather than reaching a consistent state immediately**.

This means that we need to tolerate some state uncertainty, e.g., we are not sure if we can waitlist in a train ticket waiting queue.
5.3 Final Consistency
Eventual consistency is the core idea of BASE theory. It states that ** distributed systems can remain inconsistent for a period of time, but eventually converge to a consistent state. **
It is not like strong consistency, which requires partitioned data to be consistent in real time, resulting in a costly synchronization of system data. It is also not like weak consistency, data updates are not guaranteed to be consistent, resulting in subsequent requests can only access the old data.
Most of the current industry’s distributed systems, and even relational database systems, are realized with eventual consistency. For example, MySQL’s master-slave backups use binlog logs and listening threads to keep the data in the slaves and masters eventually consistent over time.

In a nutshell, the BASE theory actually sacrifices strong consistency of data across nodes and allows data from different nodes to be inconsistent over time to obtain higher performance and high availability.
In a monolithic system, databases can still achieve strong consistency of transactions through ACID, but distributed transactions need to consider node communication delays and network failures.
Therefore, BASE theory is the scheme we often use in real distributed systems.
]]>










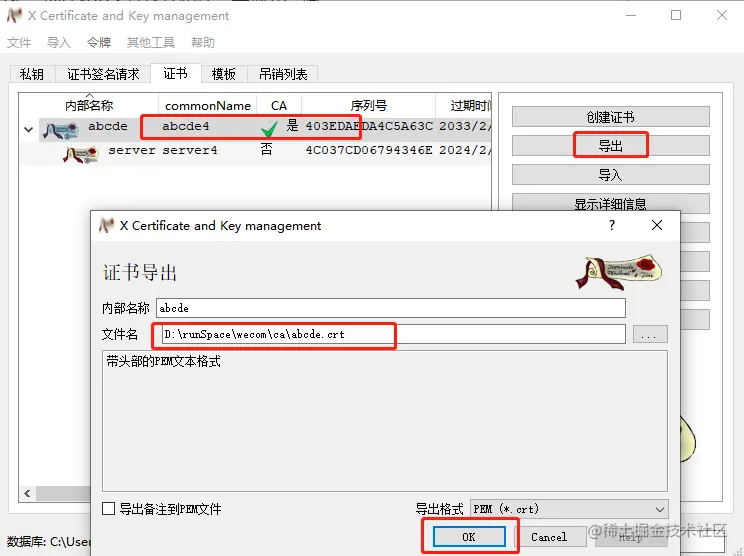
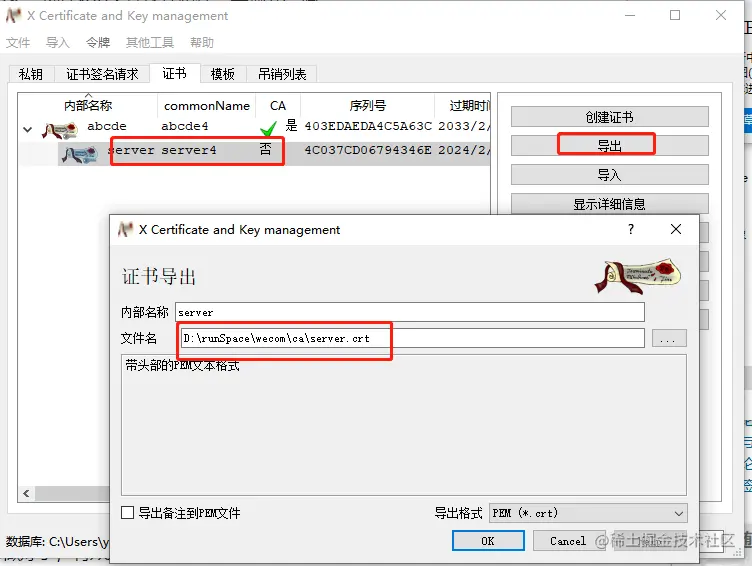
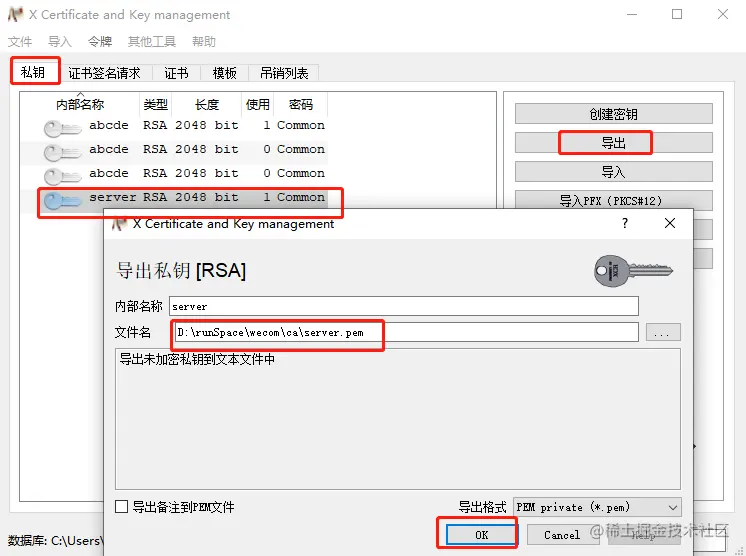
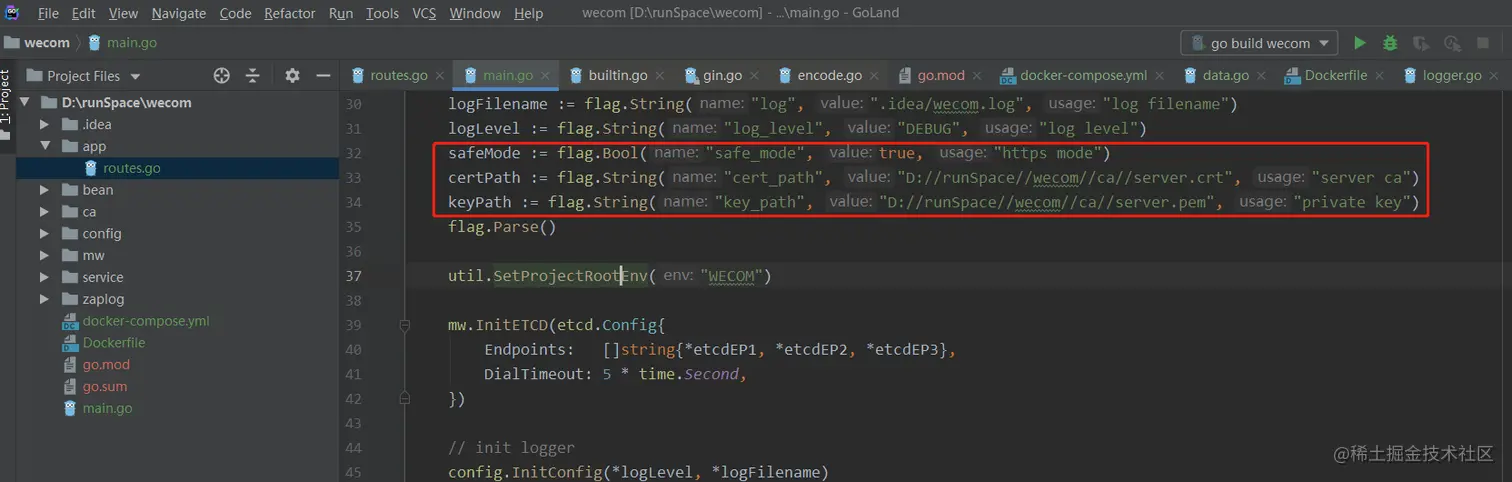
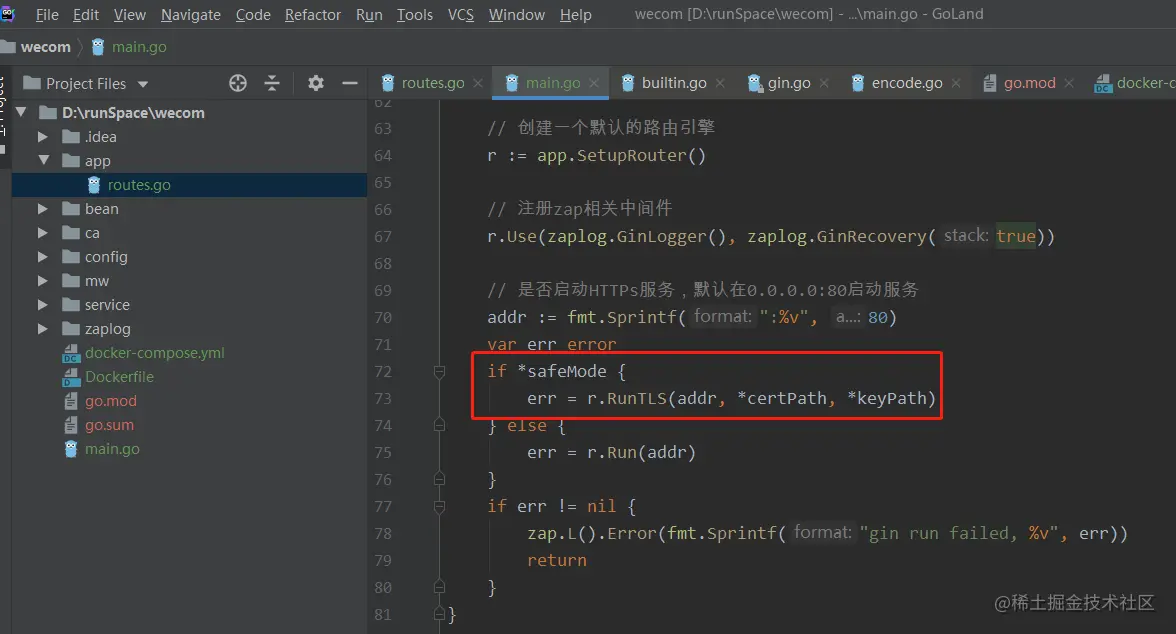








































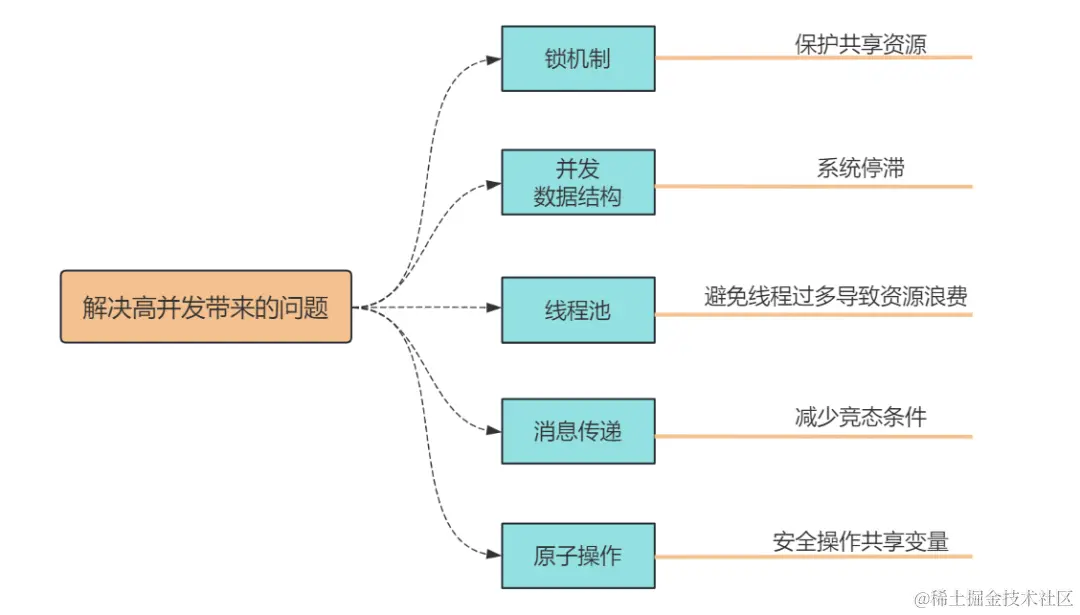




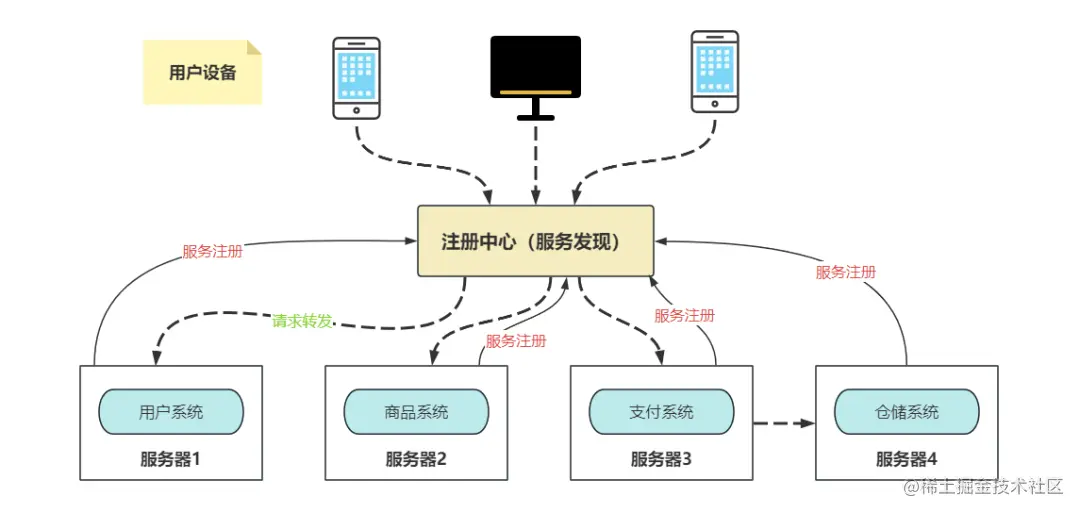




















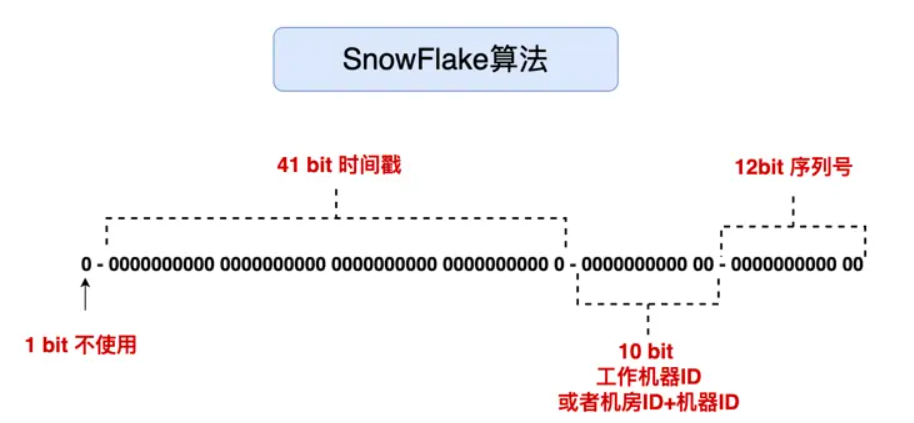








 Each element of the
Each element of the 



















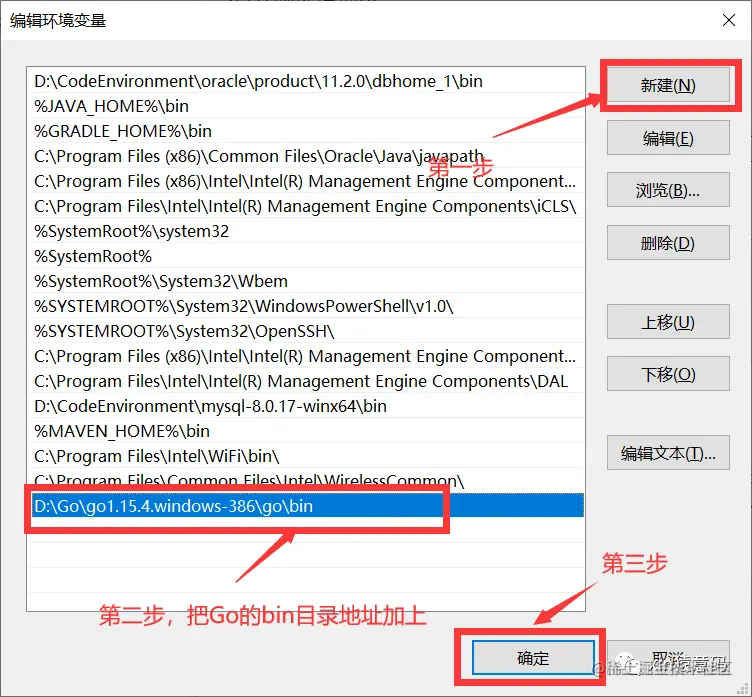







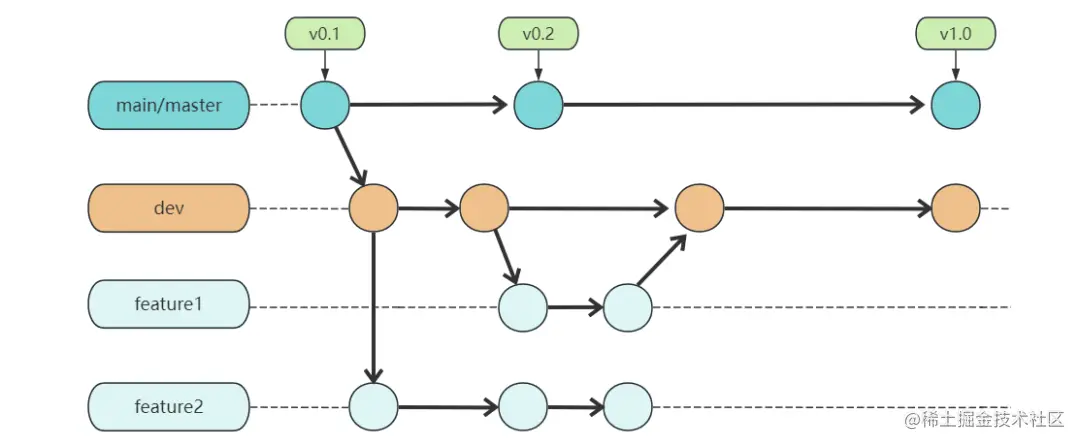
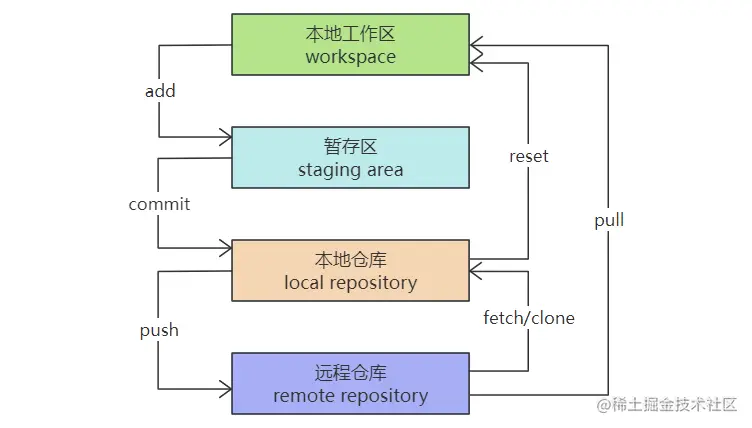
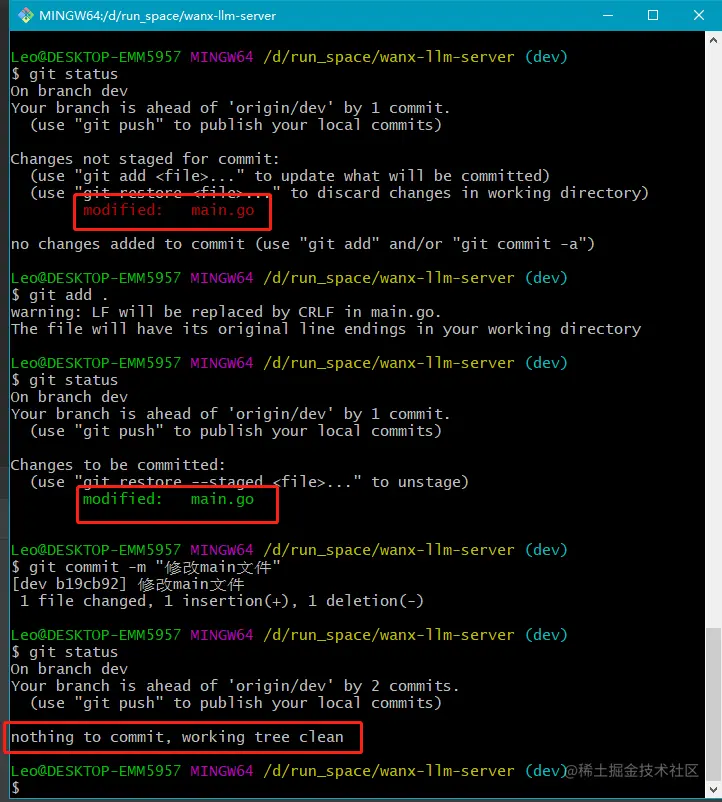
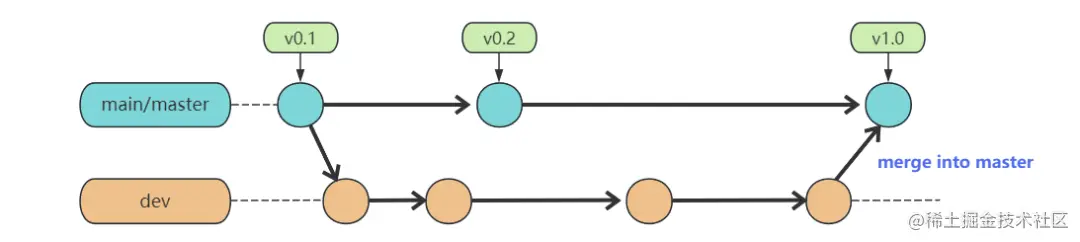
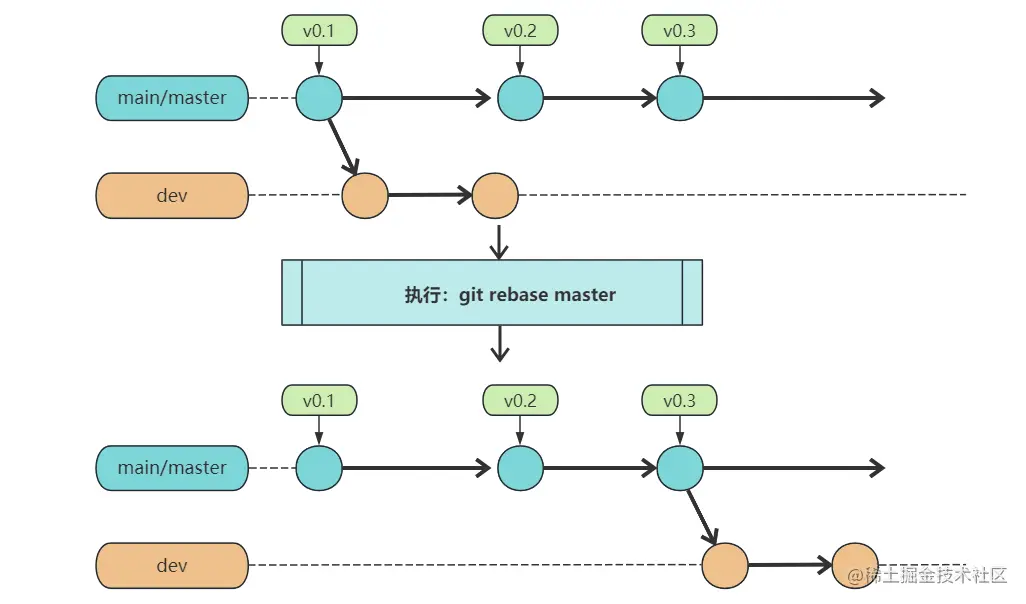
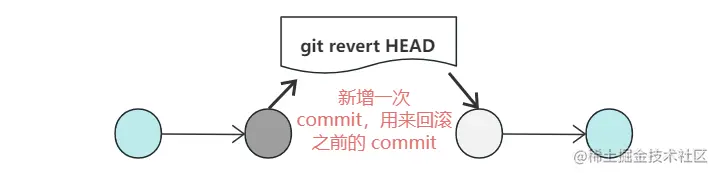
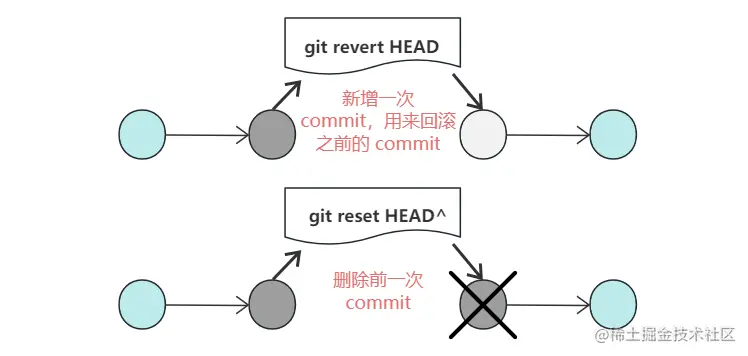















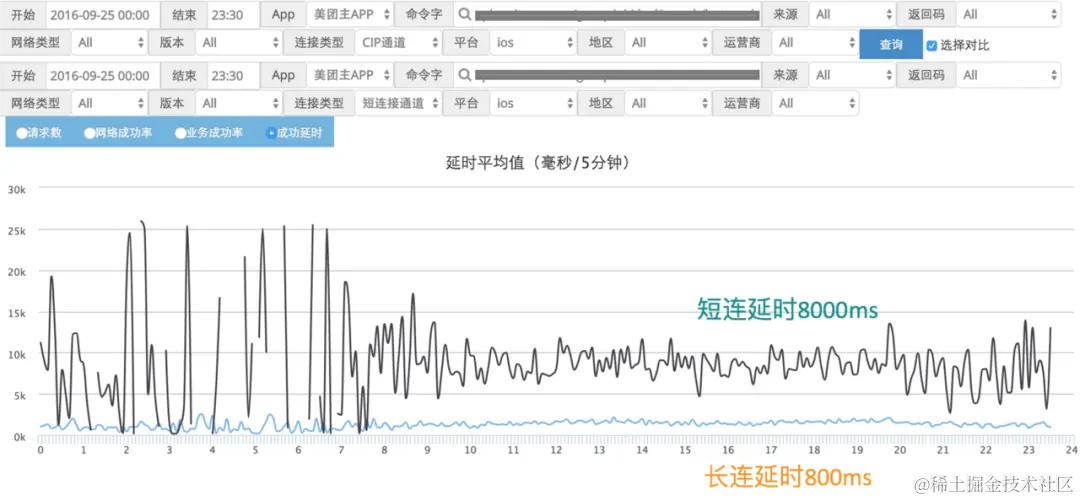








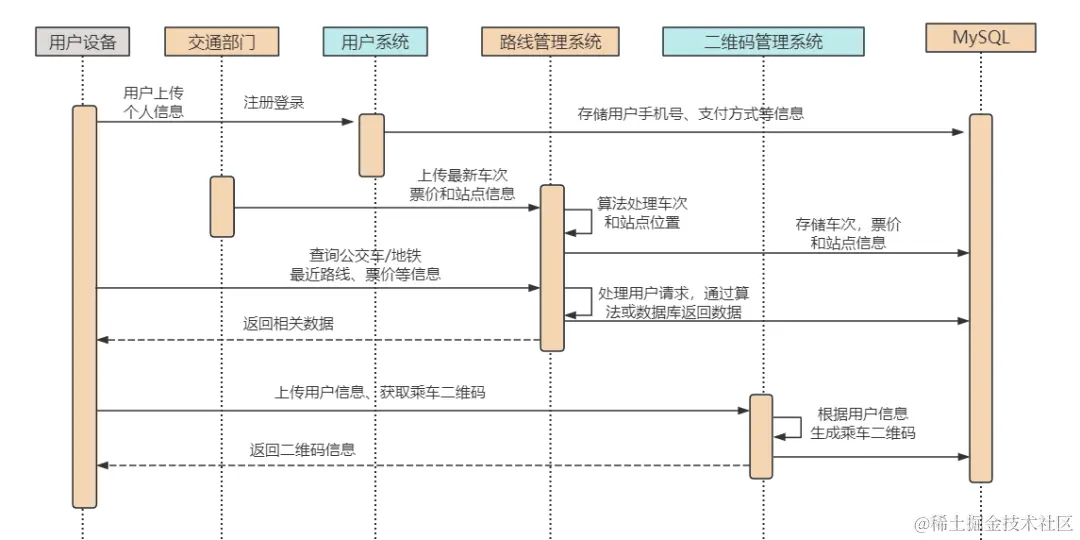
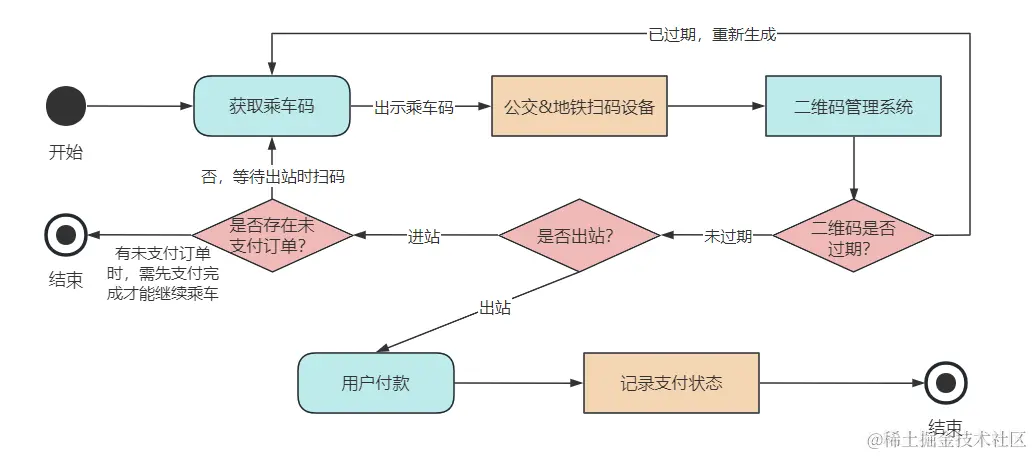





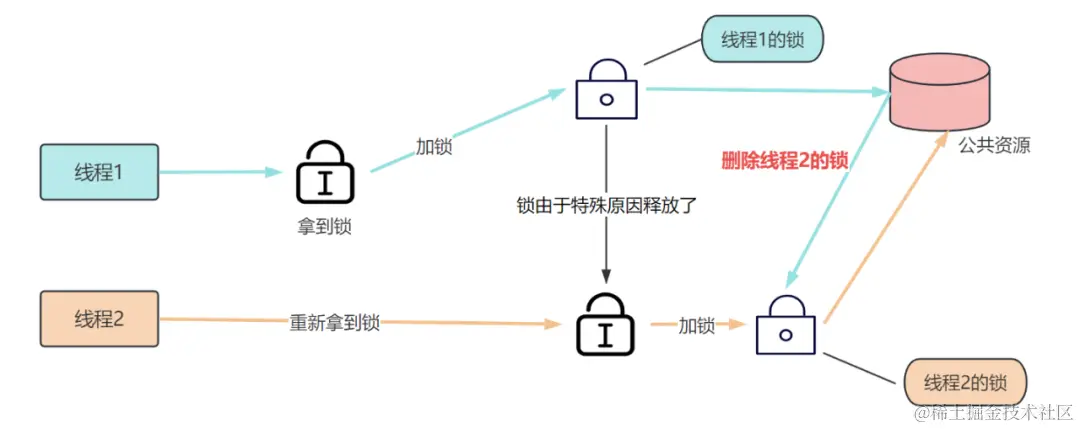

















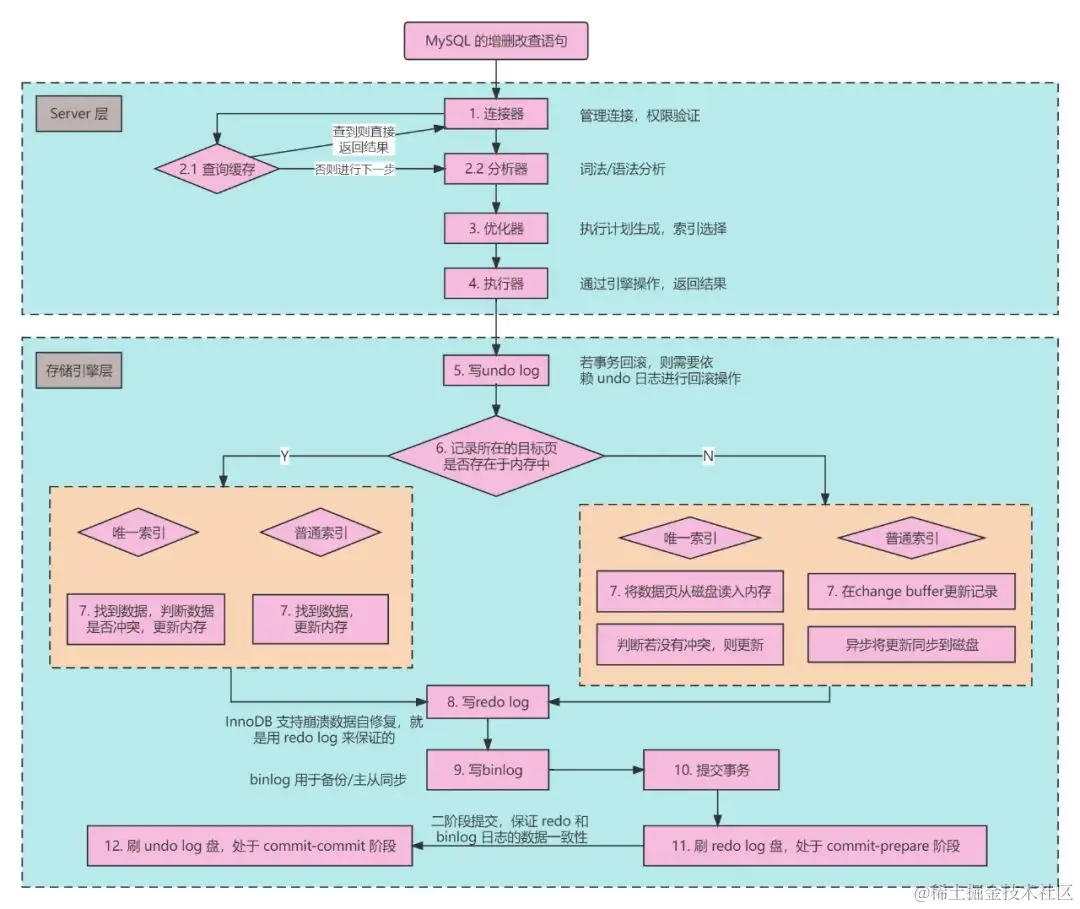








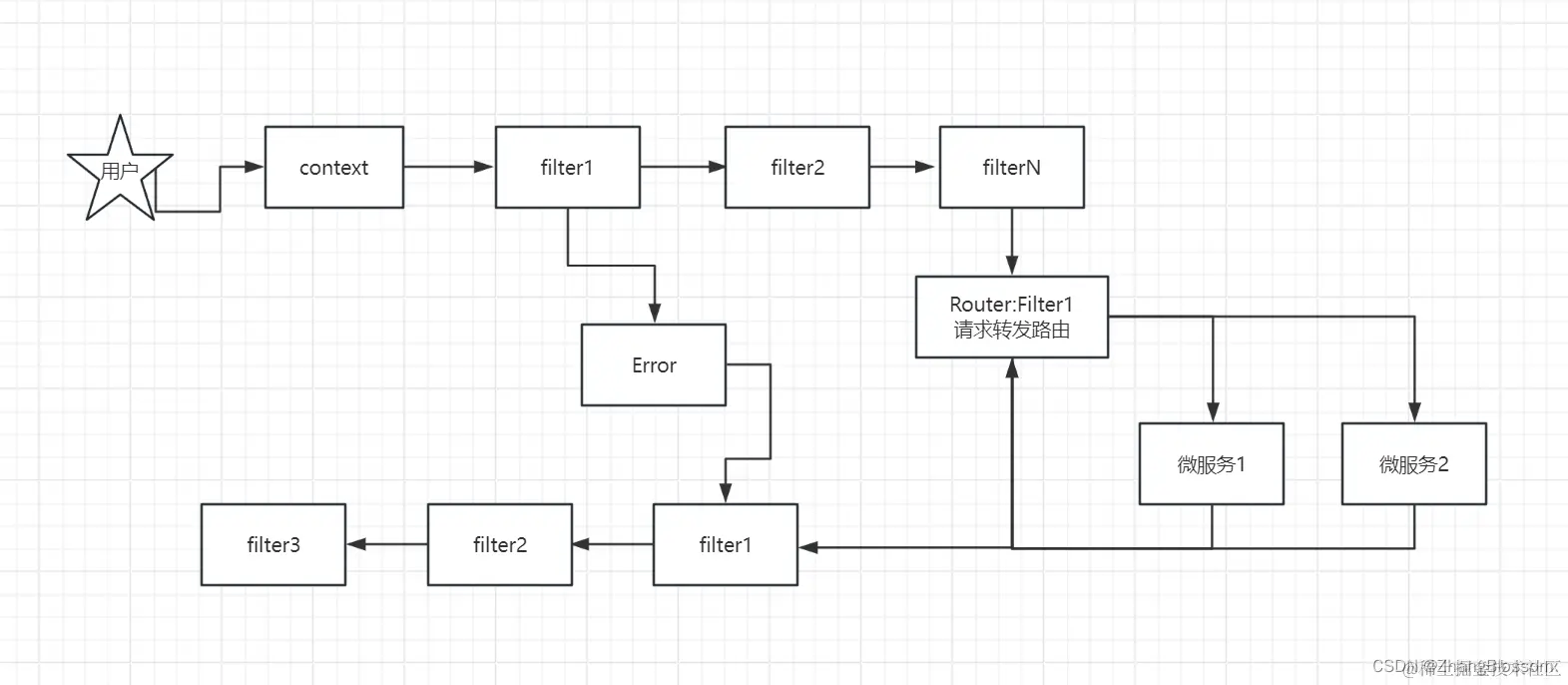
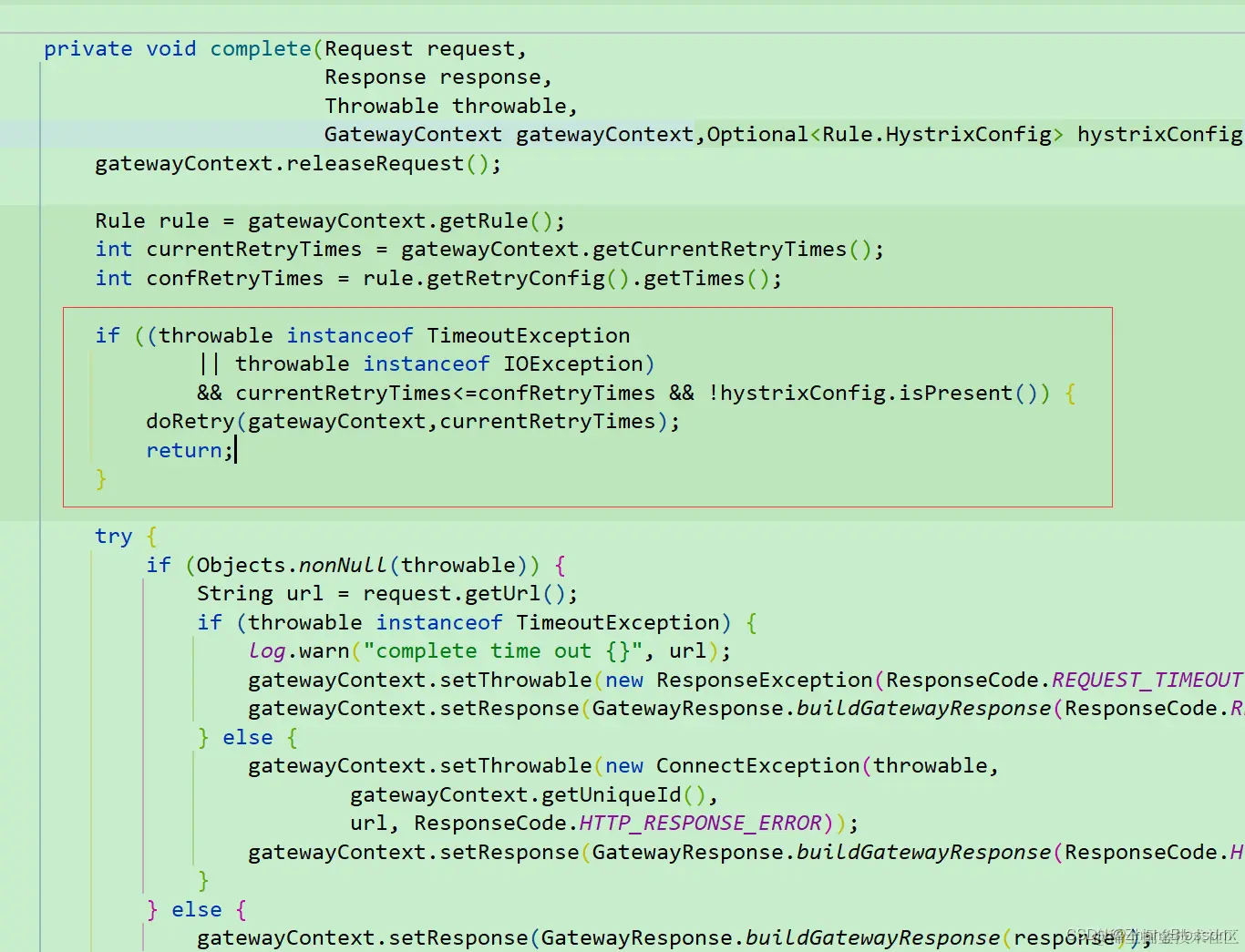 And the retry code, in fact, calls the doFilter method again to execute the logic in the route filter
And the retry code, in fact, calls the doFilter method again to execute the logic in the route filter The simple implementation of retries is relatively straightforward, provided of course that you understand all the previous code. Or at least understand the request forwarding piece of code
The simple implementation of retries is relatively straightforward, provided of course that you understand all the previous code. Or at least understand the request forwarding piece of code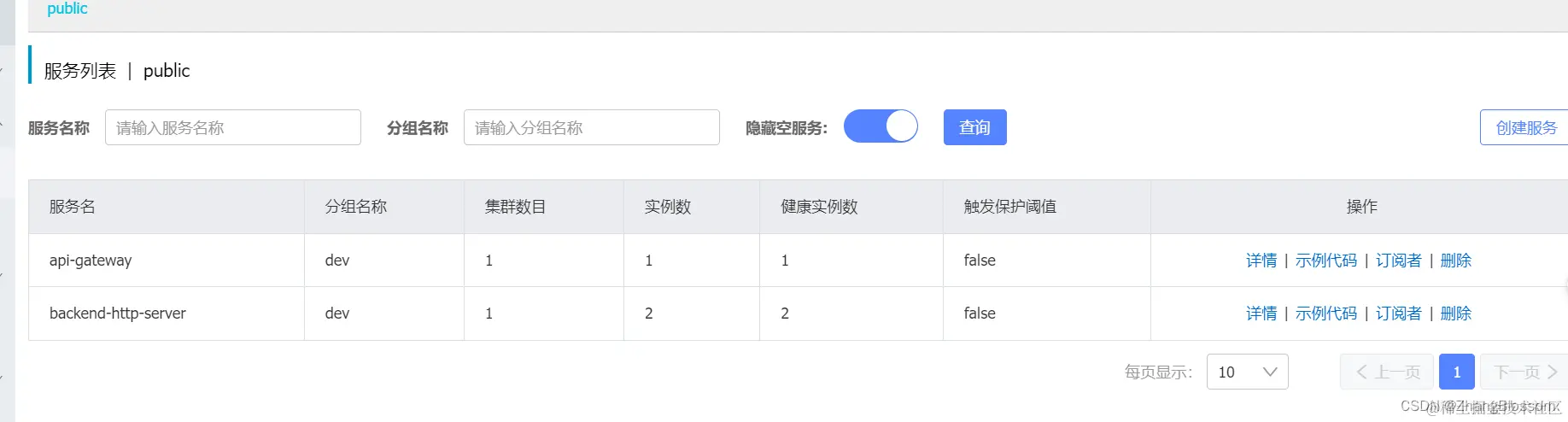
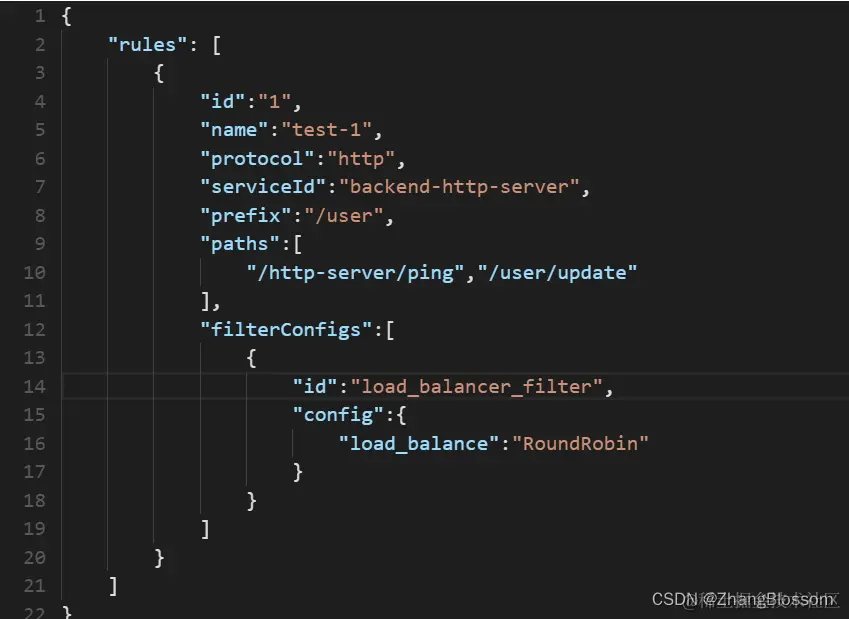 After that, we configure our request header with the name and version of the backend service to be requested
After that, we configure our request header with the name and version of the backend service to be requested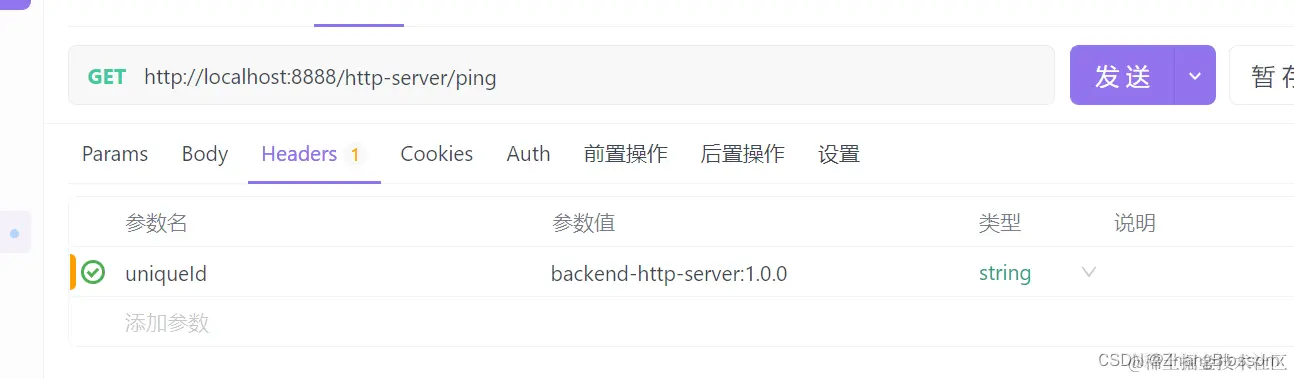 The service is sent multiple times, and here we chose polling load balancing, so you can see that the service is distributed evenly to the two back-end services at the end.
The service is sent multiple times, and here we chose polling load balancing, so you can see that the service is distributed evenly to the two back-end services at the end.
 You can get the project source code and information in the video introduction link to the effect demo
You can get the project source code and information in the video introduction link to the effect demo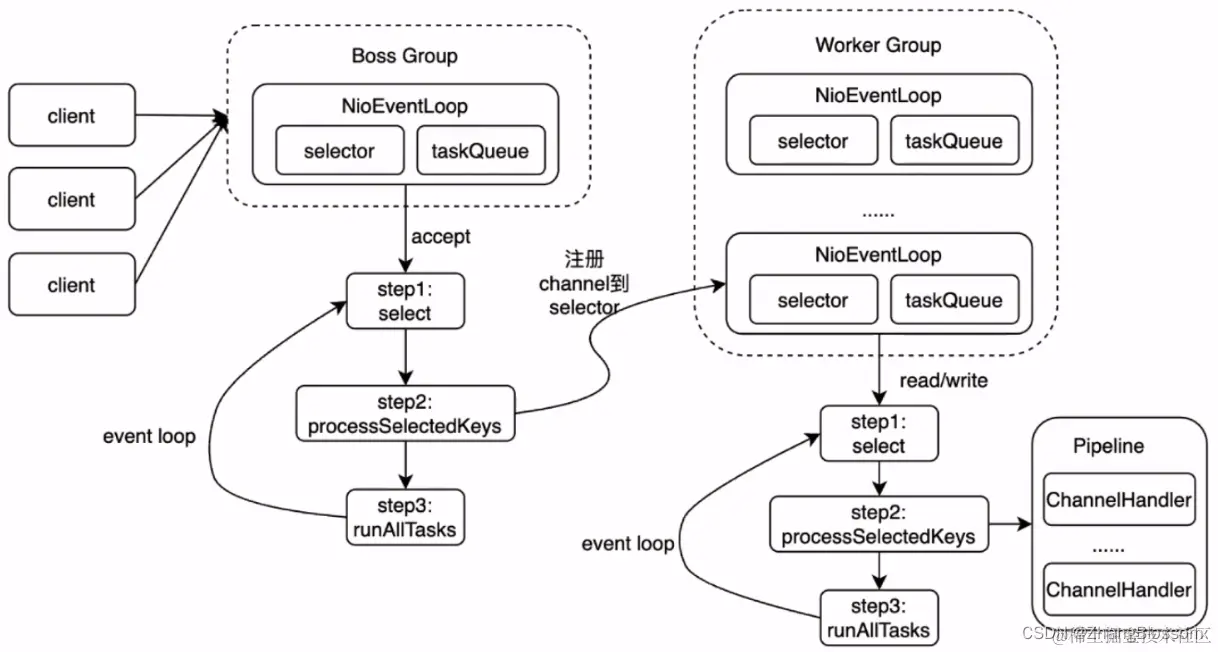
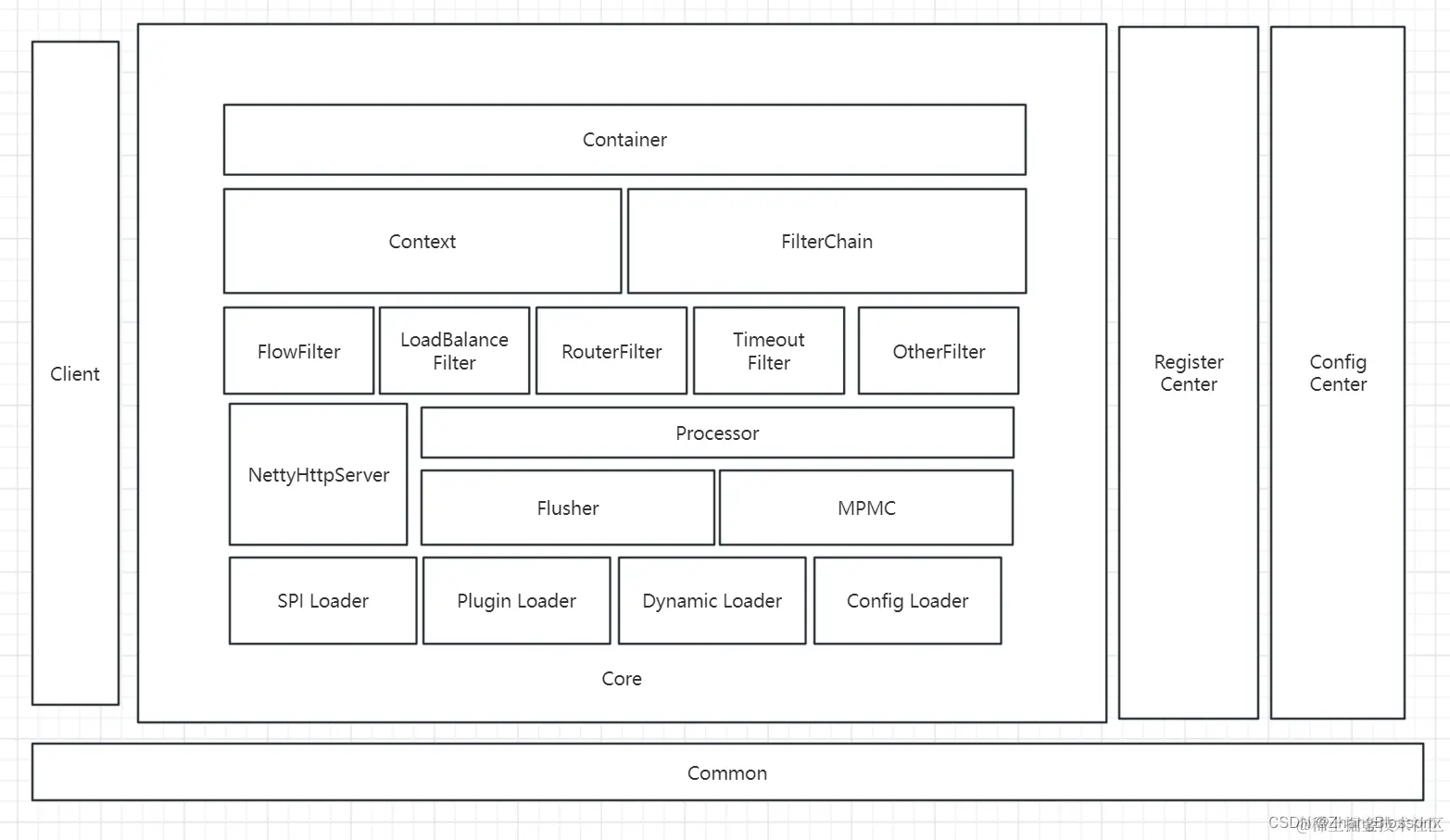 Common: Maintain public code, such as enumeration Client: Client module to facilitate our other modules to access the gateway Register Center: Registration Center module Config Center: Configuration Center module Container: contains the core functionality Context: request context, the rules FilterChain: through the Chain of Responsibility mode, chained execution of filters FlowFilter: flow control filters LoadBalanceFilter: load balancing filters RouterFilter: routing filters TimeoutFilter: timeout filters OtherFilter: other filters NettyHttpServer: receive external requests and flow internally Processor: Background request processing Flusher: Performance optimization MPMC: Performance optimization SPI Loader: Extension Loader Plugin Loader: Plugin Loader Dynamic Loader: Dynamic Configuration Loader Config Loader: Static Configuration Loader
Common: Maintain public code, such as enumeration Client: Client module to facilitate our other modules to access the gateway Register Center: Registration Center module Config Center: Configuration Center module Container: contains the core functionality Context: request context, the rules FilterChain: through the Chain of Responsibility mode, chained execution of filters FlowFilter: flow control filters LoadBalanceFilter: load balancing filters RouterFilter: routing filters TimeoutFilter: timeout filters OtherFilter: other filters NettyHttpServer: receive external requests and flow internally Processor: Background request processing Flusher: Performance optimization MPMC: Performance optimization SPI Loader: Extension Loader Plugin Loader: Plugin Loader Dynamic Loader: Dynamic Configuration Loader Config Loader: Static Configuration Loader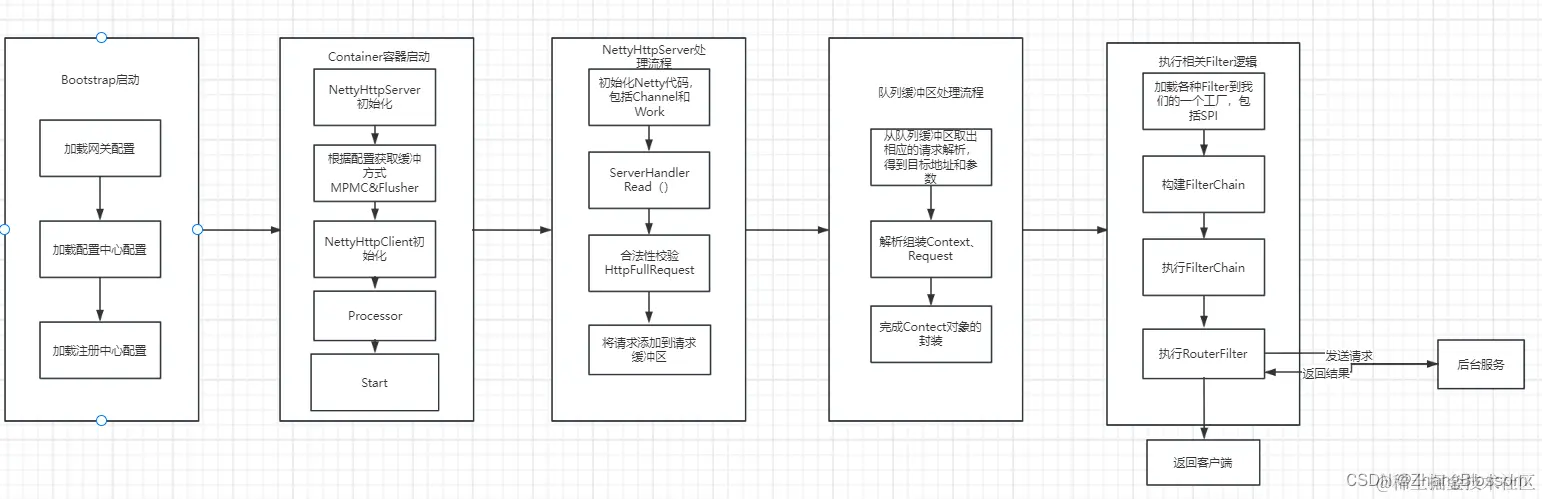 With this more detailed processing flow above, we can probably start preparing to write the code. Stay tuned for the following, which will start the actual writing of the code.
With this more detailed processing flow above, we can probably start preparing to write the code. Stay tuned for the following, which will start the actual writing of the code. The initialization of the subfactory is written as follows.
The initialization of the subfactory is written as follows. 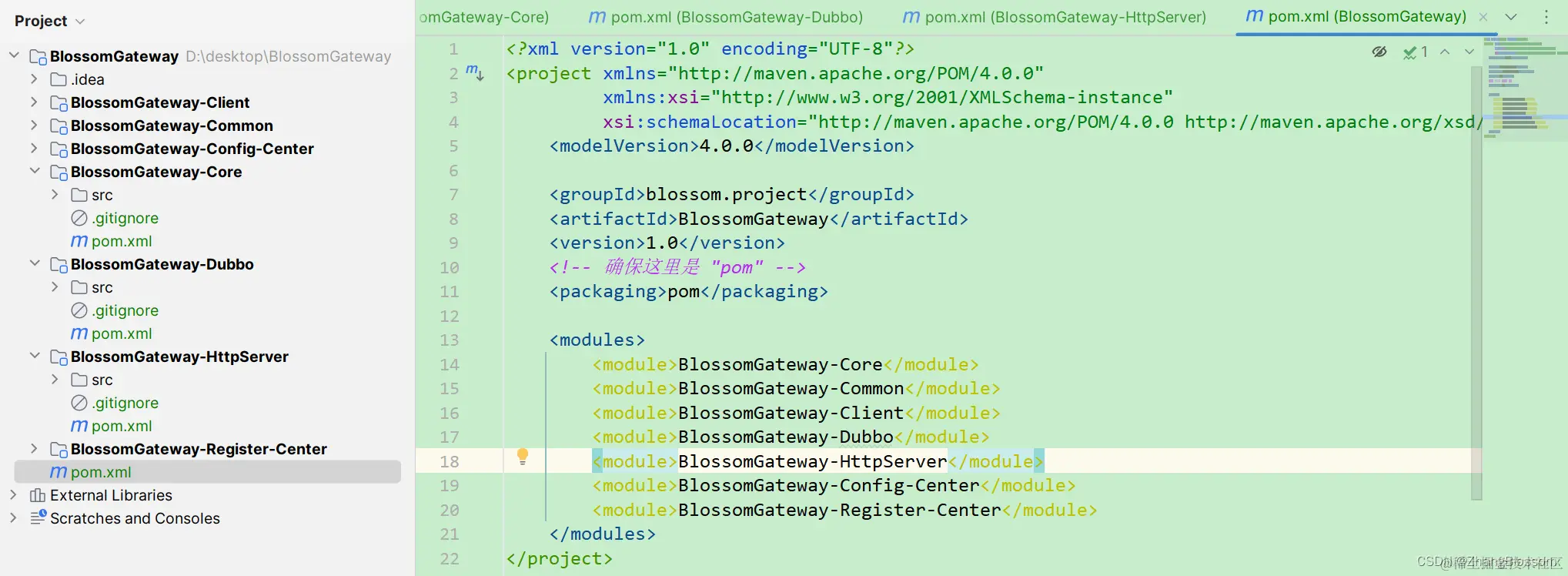 The initialization of the subfactory is written as follows.
The initialization of the subfactory is written as follows.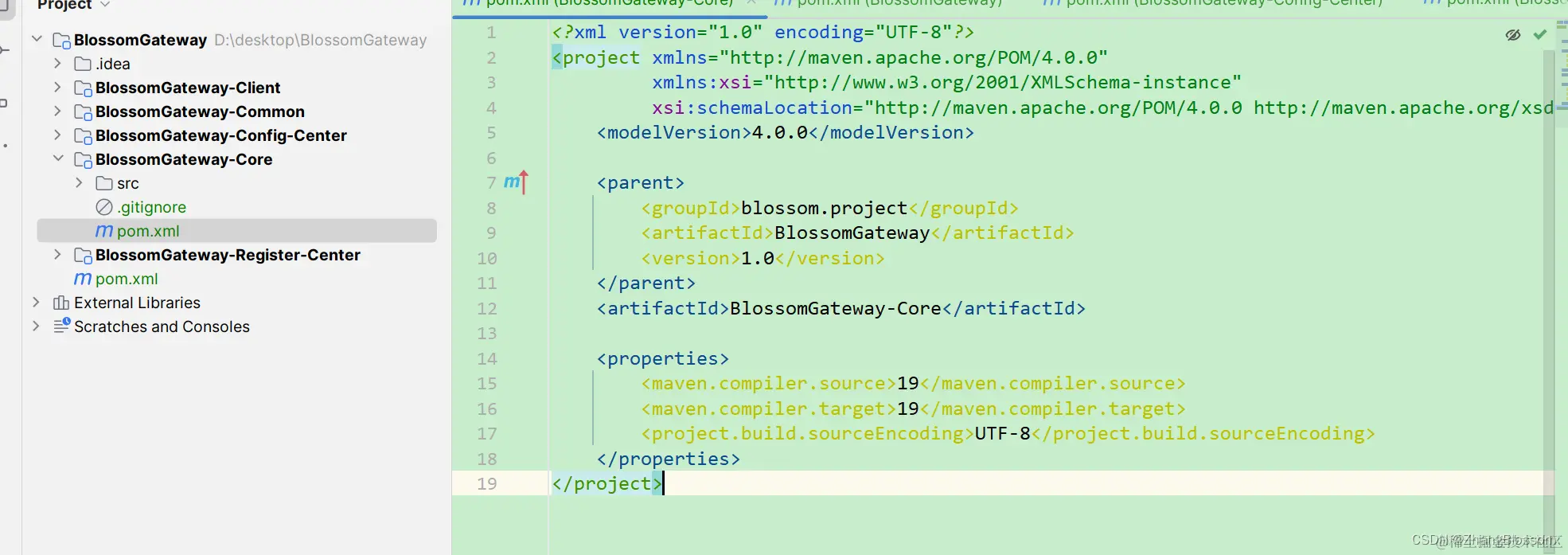 After that we can start building our starter class in our Core module.
After that we can start building our starter class in our Core module.  At this point our project skeleton has been built.
At this point our project skeleton has been built. I won’t post the exact code implementation here. But I will briefly introduce why these classes are needed here. Let’s start with IContext, this is the top-level interface class for gateway contexts, which defines a number of methods. The role of this class is mainly to qualify some basic operations of the current gateway request. For example, whether the current gateway request is normally executed, or whether there is an exception, whether the request is a long connection, whether the request has a callback function and so on. After the Context is the internal Request and Response implementation. That is, the realization of the gateway request and gateway response information. Gateway request information includes the gateway’s global start and end time, request id, request path, request host, path parameters, request body parameters, cookies, and the gateway will be forwarded to the back-end service after processing the information. The gateway response information includes response content, response status code, and asynchronous response object. After that, we need to set a rule to filter. And the rules are organized.
I won’t post the exact code implementation here. But I will briefly introduce why these classes are needed here. Let’s start with IContext, this is the top-level interface class for gateway contexts, which defines a number of methods. The role of this class is mainly to qualify some basic operations of the current gateway request. For example, whether the current gateway request is normally executed, or whether there is an exception, whether the request is a long connection, whether the request has a callback function and so on. After the Context is the internal Request and Response implementation. That is, the realization of the gateway request and gateway response information. Gateway request information includes the gateway’s global start and end time, request id, request path, request host, path parameters, request body parameters, cookies, and the gateway will be forwarded to the back-end service after processing the information. The gateway response information includes response content, response status code, and asynchronous response object. After that, we need to set a rule to filter. And the rules are organized.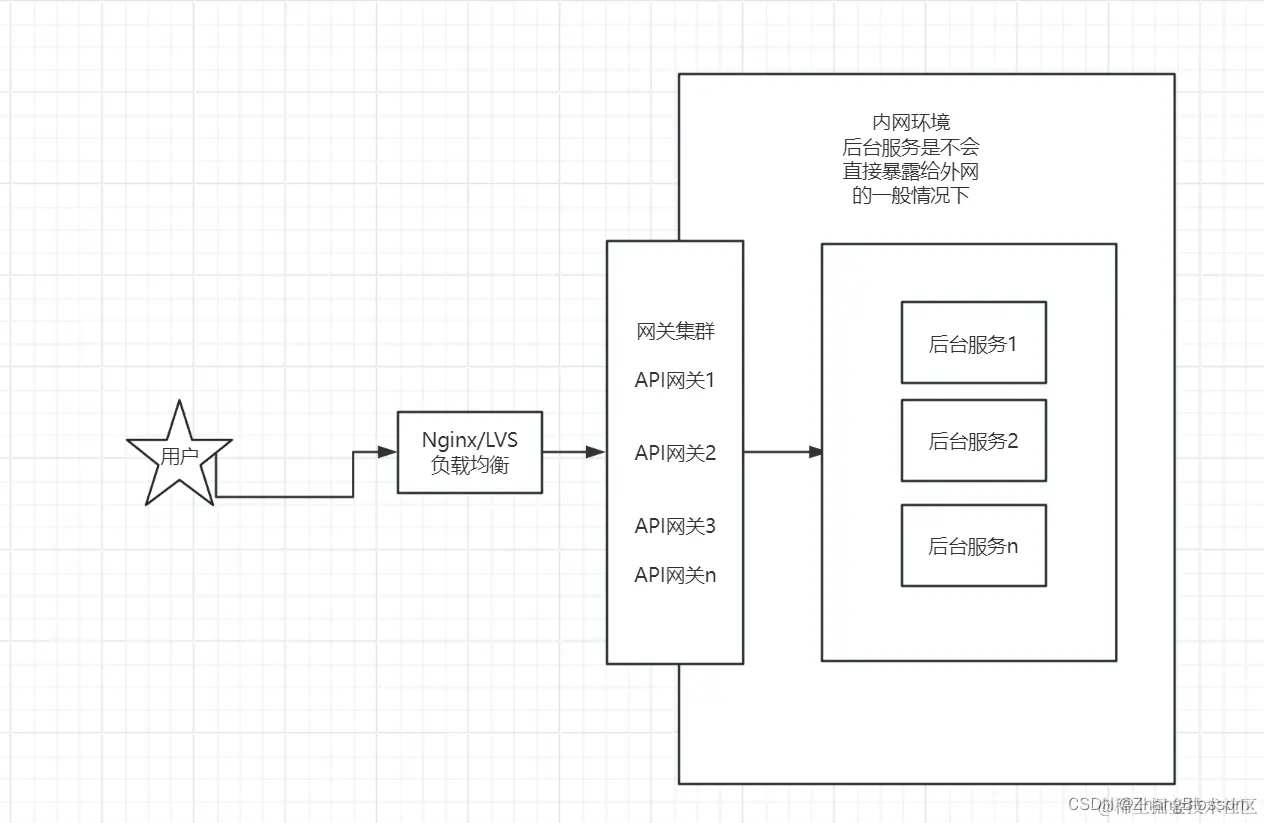 In order to further realize high availability, we also need to solve the case of manual switching of the crashed service manually, that is, to realize the hot-switching of the master and the backup, and to realize the switching automatically when the service fails. We can determine whether the service is alive through regular heartbeat detection. If the service is not alive, then we will remove the service from the list of registries and so on, so that it will not be accessed for the time being, and then we carry out repair and maintenance of the downed service, and restart the project.
In order to further realize high availability, we also need to solve the case of manual switching of the crashed service manually, that is, to realize the hot-switching of the master and the backup, and to realize the switching automatically when the service fails. We can determine whether the service is alive through regular heartbeat detection. If the service is not alive, then we will remove the service from the list of registries and so on, so that it will not be accessed for the time being, and then we carry out repair and maintenance of the downed service, and restart the project.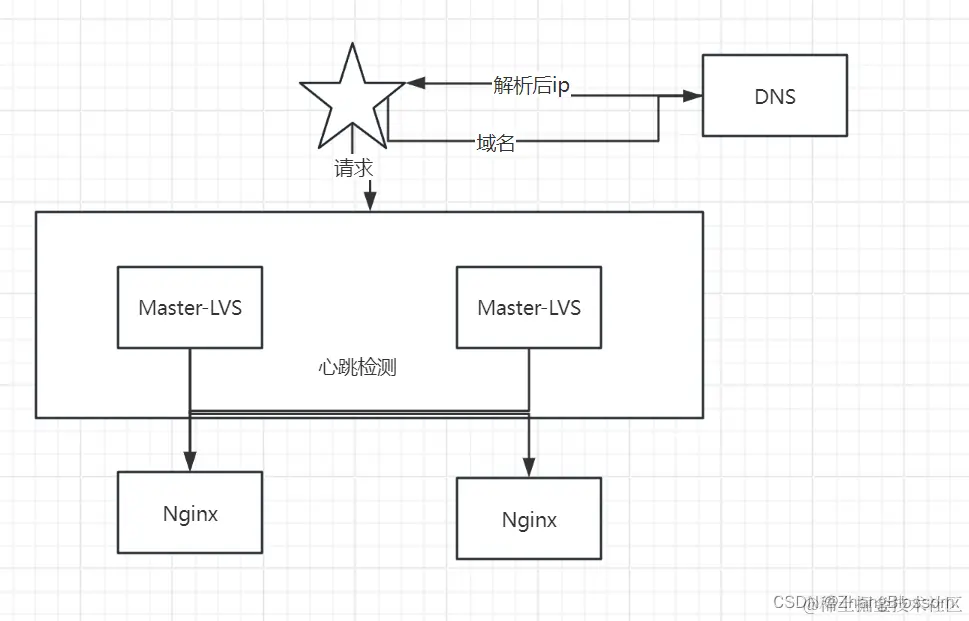
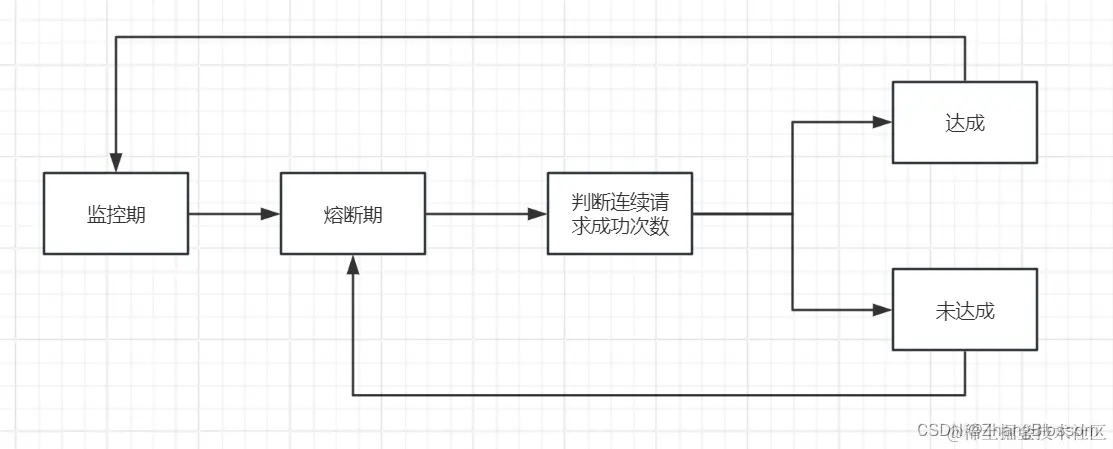
 This article, as the first article of my gateway, does not involve any code, but just mentions the role of the gateway and why I want to develop my own gateway, and the subsequent articles will be updated continuously. If you need, please watch the demo effect video to get the corresponding full information.
This article, as the first article of my gateway, does not involve any code, but just mentions the role of the gateway and why I want to develop my own gateway, and the subsequent articles will be updated continuously. If you need, please watch the demo effect video to get the corresponding full information.


 The general case can be described only for important requirements, the use case statute for critical use cases. General requirements can be ignored. (They should never be ignored in the PRD)
The general case can be described only for important requirements, the use case statute for critical use cases. General requirements can be ignored. (They should never be ignored in the PRD)

 Flowcharts are more flexible in the way they are drawn. The following are personal experiences and habits
Flowcharts are more flexible in the way they are drawn. The following are personal experiences and habits










 For method calls within the project, module dependencies, we can quickly sort out the upstream dependencies. For example, using IDE shortcuts. However, in the case of microservices, we need to obtain the call chain diagram, and we can only rely on the service governance framework and code scanning tools to sort out the upstream dependencies of each interface.
For method calls within the project, module dependencies, we can quickly sort out the upstream dependencies. For example, using IDE shortcuts. However, in the case of microservices, we need to obtain the call chain diagram, and we can only rely on the service governance framework and code scanning tools to sort out the upstream dependencies of each interface.
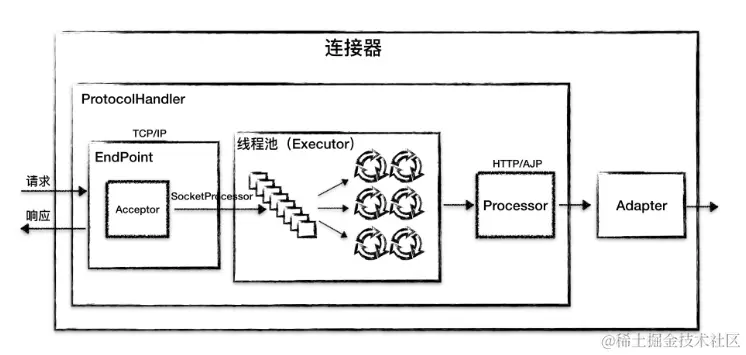
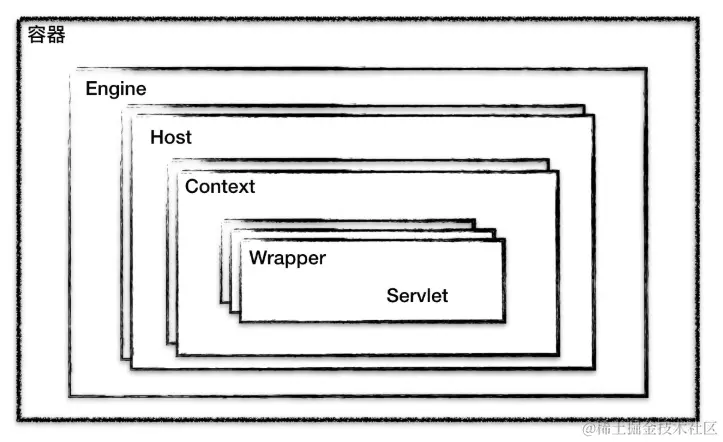
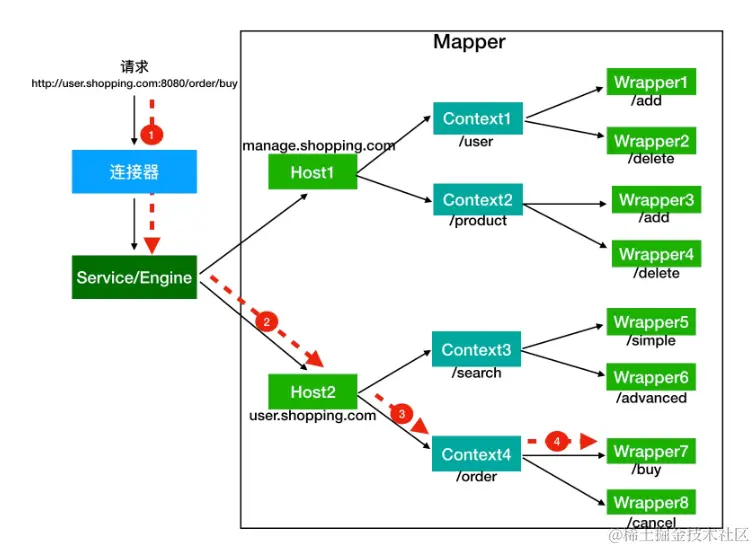
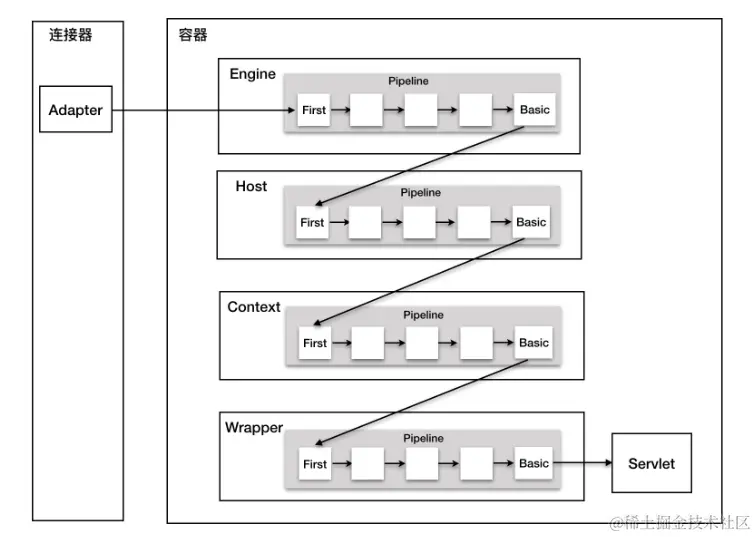
















































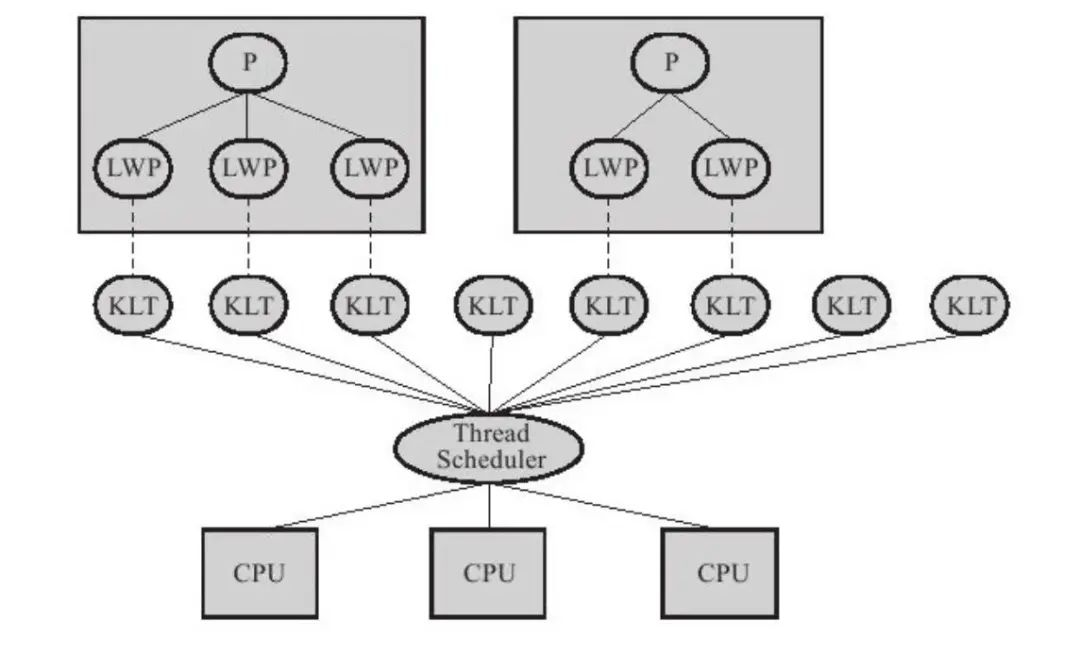
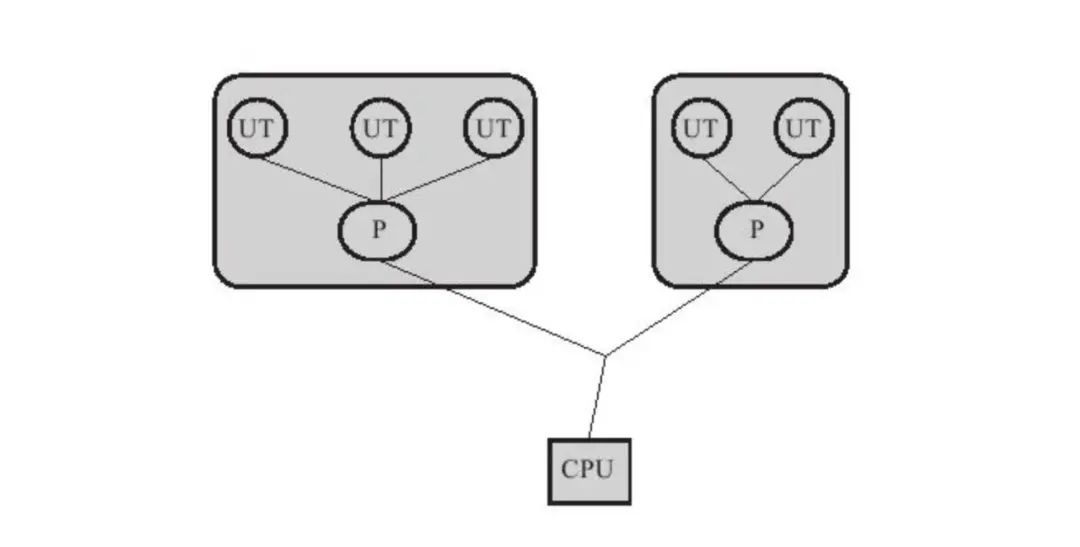
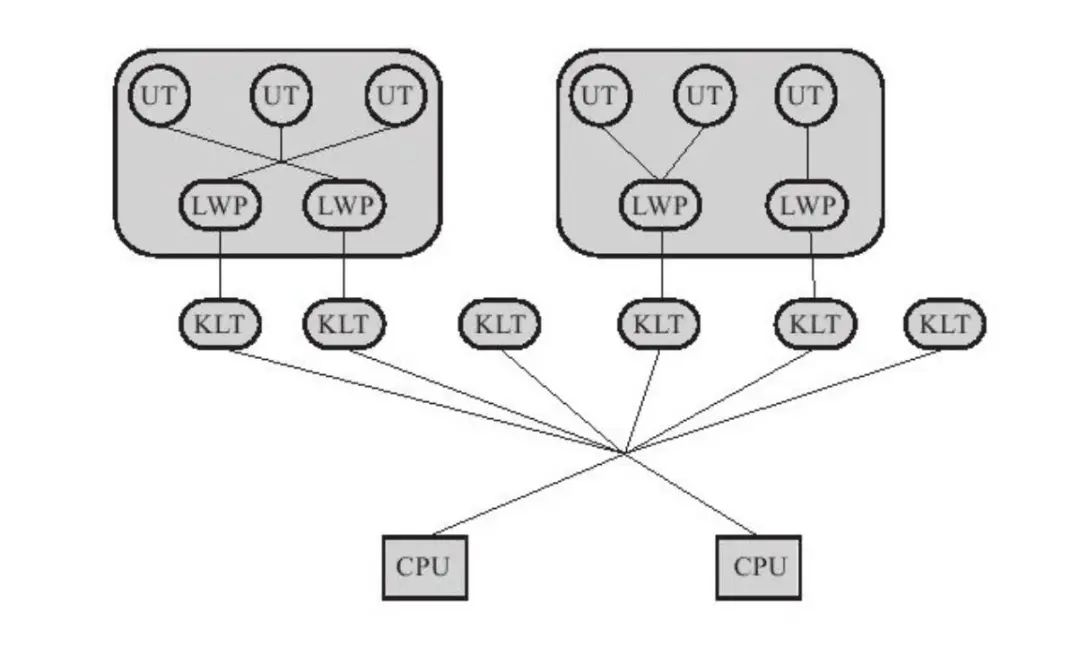





































































































































 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/7744/0*Gwdgc_fcR7ZgGNnb)


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
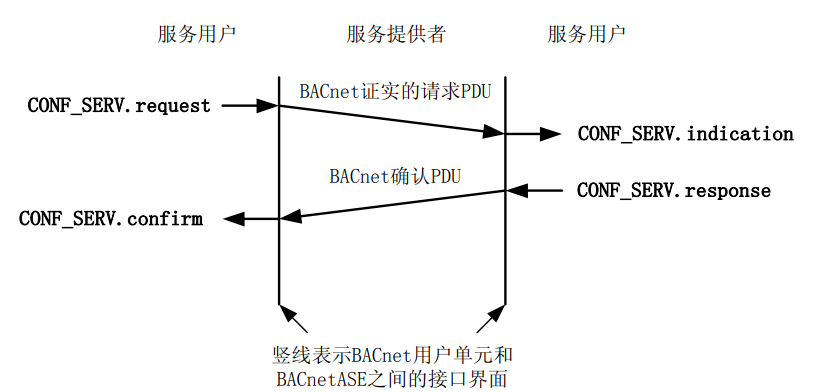{kind=link}
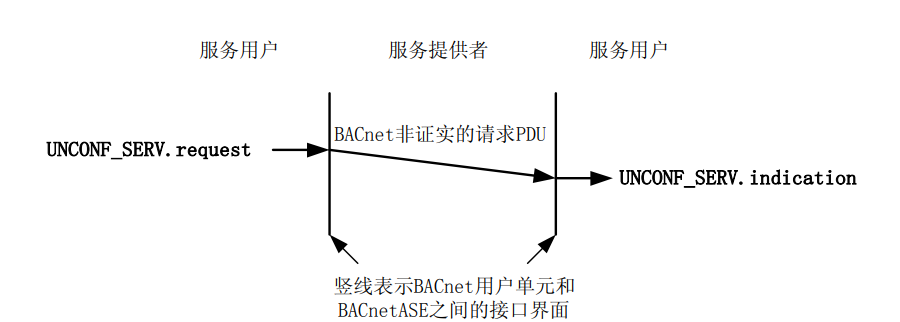{kind=link}
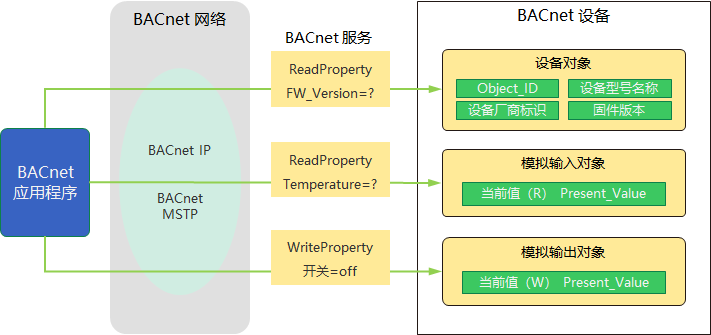{kind=link}
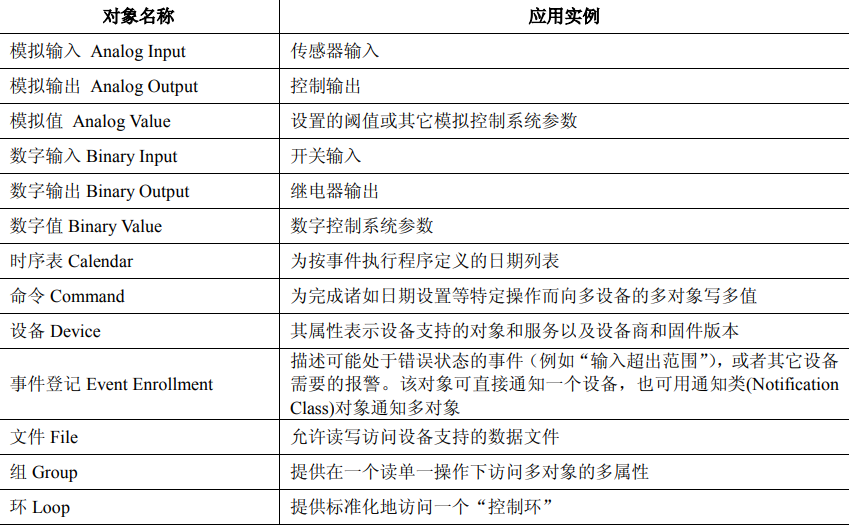{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}