
I hear you've studied architecture? Come on, let's make a microblogging system.
Table of Contents
- Introduction
- Requirements Analysis
- Outline Design
- Detailed Design
- Publish/Subscribe Issues
- Postscript
1. Introduction
When I interviewed for the “Baidu.com” department’s “Backend Senior Development Engineer” a year ago, I was quite impressed by one of the interview questions during the third interview.
I remember that the interviewer was very professional, asked a lot of project-related and thoughtful questions, and a few of my usual development process in the accumulation of high-quality BUG, also asked.
I was complacent, thinking that the test will be, answered all right, the interviewer began to make things difficult: “Since you think quite a lot on the project, then I will test you on a project design topic! First of all, these questions are not meant to be difficult for anyone, but just to see the depth and breadth of the candidate’s technical knowledge!”
Translated with www.DeepL.com/Translator (free version)
“Ah, right, right, right! It’s like this”, although the heart of a hundred apprehensions, it is true that the daily requirements are CRUD (add, delete, change, and check), the architectural design has not been done in the project for a long time, but still showed no panic, the color of a ready mind.
After all, the interview book said: half of the time in the interview are playing psychological warfare! As long as you do your homework, you can defend yourself confidently in the examination room, and we won’t be defeated by the interviewer’s one or two hour attack.
2. Requirements Analysis
The interviewer asked, “As a popular social APP, do you usually use Weibo? Can you tell me a few common functions of microblogging?”
Microblogging has not really been used much, but I just recently read a system design plan about microblogging, so I answered without panic: “The common functions of microblogging are brushing microblogging, posting and user attention, in addition, users can also like, comment, favorite and forward microblogging.”
“Good, then if you are now allowed to design a microblogging system, combined with the several core functions you just said, how would you design it? The system needs to be considered for high concurrency, high performance, and high availability.”
After getting the “Product Requirements”, I first built a use case diagram of the core functions in my mind as follows:
Translated with www.DeepL.com/Translator (free version)

Each requirement is described as follows:
- Brush microblogging: users open the microblogging homepage on the mobile APP side, displaying the most recent microblogs published by the friends they follow, sorted by the most recent time;
- Tweeting: Users can post content up to 140 characters of text, which can contain pictures and videos;
- Follow friends: users can follow other users, and the followers can see the information and number of followers.
3. Outline Design
The business functions of Weibo are not difficult to understand, but ** the concurrency and data volume** are very large:
- 1 billion level of user volume, on average thousands of post counts per user, each user can follow thousands of friends;
- high concurrency, the average page access of 100,000 level per second, the posting volume of 10,000 level per second;
- Uneven distribution of users, the number of posts or the number of fans of some star users exceeds that of ordinary users by several orders of magnitude;
- Uneven distribution of time, a user may suddenly become a hot user at a certain point in time, and its fans may also steeply increase by several orders of magnitude.
It has the characteristics of a typical social system, which can be summarized into three points: massive data, high access, non-uniformity, and then from its most common follow friends, brush microblogging, posting three functions to do the outline design.
3.1 Follow Friends
Translated with www.DeepL.com/Translator (free version)

If you open the main page of a blogger in Weibo, the page contains the most basic features: Ta’s followers, Ta’s fans, and we can click to follow this blogger. From the blogger’s main page, we can also access his attention and fans sub-pages:
- Attention page, which displays information about all the users that the user follows.
- Follower page, which shows all the fans of the user.
In the above page, the user can follow a certain user, and can also delete fans, that is, cancel the attention of a certain other user, the business interaction of the function is as follows:
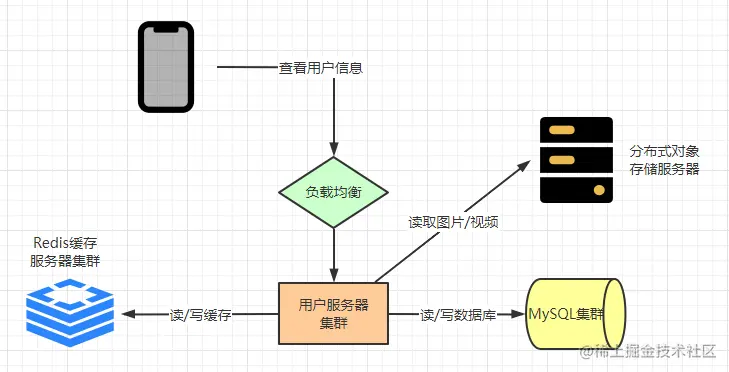
When a user follows a friend, it needs to go through a load balancing server first, and then send the request to Weibo’s user server cluster, where it involves displaying the user’s information, so the user servers may access object storage servers for images and videos, as well as take out text data from Redis or MySQL.
Finally, if the user’s follow status is modified, the information is written to the Redis and MySQL clusters.
3.2 Brush Microblogging
The core of the microblogging system is to solve the problem of high concurrency. The overall deployment model of the system is as follows:

First, we use CDN (Content delivery network) to quickly return user requests, which is based on the principle of deploying servers in regional nodes that are widely used by users, and when a user accesses the system, the request is distributed to the nearest servers through the Global Load Technique, and they provide services directly to the user:

When CDN is not used, each user request will directly reach the system’s application server cluster, which will generate great traffic pressure on the system’s servers; when CDN is used, the user requests will be distributed to the nodes in the user’s neighborhood according to the target servers returned by the CDN load balancer.
The advantage of using CDN is that it can greatly avoid network congestion and make content transmission faster and more stable. CDN can be regarded as a system cache, which is especially suitable for microblogging scenarios where data is seldom changed, and under normal circumstances, CDN can filter out more than 90% of the requests and return data directly.
Under normal circumstances, CDNs can filter out more than 90% of the requests and return the data directly. Therefore, when a user accesses the Weibo system through a CDN, the vast majority of the requests will be hit by the CDN cache. In other words, more than 90% of bandwidth-consuming requests such as images and videos can be digested by the CDN. Requests that are not hit by the CDN will arrive at the reverse proxy server in the data center, which checks whether the local cache has the content needed for the request. If there is, it will return directly; if not, it will go to the distributed object storage cluster to get the relevant images and videos, or get the microblogging text content from the application server application.
When fetching content from the microblogging application server cluster, it will first retrieve the latest tweets posted by the current user’s friends from the Redis cache server and build a result page to return. If the number of tweets cached in Redis is less than 20, it will continue to look up the data from the MySQL database.
4.3 Writing Tweets

Instead of CDNs and reverse proxies, tweets are written directly to the application server cluster via load-balanced servers. The application server writes the published tweets to the Redis cache cluster on one hand, and to the MySQL sharded database on the other hand.
Note that when we write to the database, if we write to the database directly, when a highly concurrent write request suddenly arrives, it may cause the database to overload, which may lead to system blocking or crashing (refer to the “Cache Avalanche” problem). Therefore, database write operations can be written to a message queue (e.g., Kafka cluster), and the message queue’s consumer program will consume messages from the message queue at a certain rate and write them to the database to ensure that the DB’s load pressure does not surge and cause abnormalities.
4. Detailed Design
4.1 Table Design
User, fan, follow and post tables:
- user table: primary key id, user information (name, avatar, registration time, v-authentication, cell phone number, etc.)
- relation table: primary key id, followId, attentionId [fan and follower IDs]
- post table: primary key id, userId, postTime[posting time (accurate to milliseconds will do)], content
Index Optimization
post table can use combination index userId+postTime to query the recent posts of a user, here the combination index is used as a secondary index, so it needs to go back to the table. In order to reduce the number of times to go back to the table, we can splice the userId and timestamp bit postId as the primary key: for example, the first 20 bits as the timestamp is accurate to milliseconds + the userId, converted into a hexadecimal (0-9a-zA-Z) string as the postId, which also ensures that the primary key is incremental.
However, this will cause the index tree to take up more space, and the query is not as fast as a pure numeric primary key, so you can finally choose the most suitable primary key type according to the actual situation and compare the advantages and disadvantages of the two.
4.2 Splitting a library into tables
When the data volume of follow, attention, and user tables exceeds 10 million or 100 million, the pressure of microblogging to read and write the database is very large, which is definitely not bearable for a single database. Therefore, the microblog DB needs to be a distributed database with sharded deployment.
Vertical Table Splitting
The above relation table [id, followId, attentionId] stores the information of followers and attention, when the number of users increases, there will be a problem, that is, it is not easy to choose the key for splitting the database and table:
- If followId is chosen as the hashKey, the query for the current user’s attention list will be on the same slice, but the query for all of the user’s followers will need to be on multiple slices;
- If we choose attentionId as hashKey, we will be on the same slice when querying all followers of a user, but we need to be on multiple slices when querying all followers of the current user.
So we split the relation table into:
- follow table: primary key id, userId, followId
- attention table: primary key id, userId, attentionId
Horizontal Splitting
Horizontal splitting means deploying a distributed database using hash slicing, the slicing rules can be user ID or post ID.
If you slice by user ID, all the posts made by the same user will be saved to the same database server. The advantage is that when the system needs to find out the tweets made by a certain user, you only need to access one server to accomplish it. The disadvantage is that for a star user, there will be a lot of data access, and the access of hot data leads to excessive load pressure on that server. Similarly, if a user posts tweets frequently, this can lead to excessive data growth on a single server.
If you slice by post ID, although you can avoid the hotspot aggregation problem caused by user ID slicing, when looking up all the microblogs of a user, you need to access a randomly sliced database server, which puts too much pressure on the entire database server cluster.
All things considered, the hotspot problem caused by user ID sharding can be improved by optimizing caching. The problem of frequent tweets by a certain user
4.3 Hot Users Problems
After splitting the table, although the problem of fast table checking has been solved to some extent, the query for some hot star users still needs to be optimized. For example, the following scenarios:
- The hot star user has a lot of fans, and the number of rows scanned when querying the number of fans by following the table to query count is very large, and this inefficient operation will be expanded due to the increase in the number of fans.
- When brushing microblogs, star users have many posts that are repeatedly viewed, if they go to the DB to get them every time a fan goes to query, there will undoubtedly be serious performance pressure.
To solve the DB query problem in the above two scenarios, caching can be introduced. But the cache space is limited, we necessarily can not cache all the data, set a good cache elimination strategy is the focus of our discussion.
Time Elimination Strategy
For hot topics, both hot posts and hot users need to be added to the cache, and the cache elimination strategy can be set as a time elimination algorithm.
All the tweets published in the last n days are cached, and when a user refreshes the tweets, he/she only needs to find them in the cache. If a user gets a list of 10 tweets, it will be returned directly to the user; if the number of tweets in the cache is not enough, it will be looked up in the database.
So, we can cache all the tweets published within 7 days, where the cache key is the user ID and the value is the list of post IDs published in the last 7 days. At the same time, the post ID and post content are also cached as key and value respectively.
Local Cache Mode
In addition, for especially popular microblogs, such as celebrities getting married/divorced/growing up in a GUI, high concurrent accesses are concentrated on a single key, which puts a great load pressure on a single redis server. Therefore, microblogging system can enable local cache mode, i.e., the application server will cache popular microblogs in the server memory, so that when users brush microblogs, it will prioritize checking whether the microblogs corresponding to the post IDs are in the local cache or not.
For big V users with more than 500w followers, we can cache all their tweets published within 48 hours to further reduce the pressure of checking hot data.
5. Microblog Publishing/Subscribing Issues
The publish/subscribe problem is the core business problem of Weibo, which is how to quickly get the latest content of all friends after following them.
5.1 Push Mode
When a user publishes a post, he/she immediately pushes the message to his/her fans. However, at this time, the fans are not necessarily online, so the data needs to be stored. In this way, every time a user adds a new post, the user needs to push the post to the slice of the DB where its followers are located, and the followers can directly query the data stored in their own slice every time they browse the new message.
An obvious problem with the push model: ** If a user has tens of millions of followers, then every time the user posts a tweet, he needs to insert tens of millions of records into the subscription table, i.e., “write proliferation “** . There is no lack of zombie fans (users who are online very infrequently) among the followers, which brings the consequence that the database is under very high pressure, leading to blocking or crashing.
5.2 Pull Mode
When a user publishes a post, it is only saved in his/her own business table. When the followers come online, they go to the followers table to read the posts and return them in chronological order.
The problem of pull mode is: if a user follows 500 star users, each time the query needs to go to each slice to query the posts published by different stars, ** a star has tens of millions or even billions of fans, which means that there may be tens of millions or even billions of read data operations at the same time, i.e., “read diffusion “** , the problem is that the database slice of the read data decompression is not reflected in the effect.
Therefore, the microblogging system firstly needs to limit the number of users’ attention, the microblogging ordinary users’ attention limit is 2,000 people, and the VIP users’ limit is 5,000 people. Secondly, minimize the number of database queries when refreshing the microblog page, and use the cache to read more posts.
5.3 Combination of Push and Pull
We found that even if we limit the number of friends for microblogging users, it is difficult to solve the subscription/publishing problem of the microblogging system with a single “push mode” or “pull mode”, so we finally adopt the “combination of push and pull” mode, which is realized in the following two ways.
1) Distinguish between big v-stars
For big v-star users (with more than 500w followers), in order to prevent write proliferation, we only need to synchronize the data to 100 database slices (assuming there are 100 data slices), which need at least three fields: userId, postId, postTime. no matter how many followers there are, there will be only 100 replicas, which avoids many zombie followers who will never go online due to data write. This avoids a lot of zombie fans that will almost never be online because of the data writing waste of network performance and storage resources.
For ordinary users, or continue to use the push mode, so that most users in the read the latest posts only need to read the corresponding slice of their own users can get the data.
This is a simpler way to design, but when the user is brushing the microblogging, ** the query process may need to query twice, respectively, the post information under the table of their own subscription, and the post information under the table of the concerned user’s publication **.
2) Distinguish online status
The second way is to judge push and pull according to the user’s state: if the user is currently online, push mode is used, and the system will create a list of friends’ latest published tweets for them in the Redis cache. If a friend who follows has a new tweet published, the post information is immediately inserted into the head of the list, and when that user refreshes the tweet, he/she just needs to return this list.
If the user is not online, the system deletes the list, and when the user logs in again to refresh, the list is rebuilt for them using pull mode.
How to determine the user online? On the one hand, it can be determined by the time interval of user operation, i.e. heartbeat mechanism; on the other hand, it can also be predicted the online time of the user by machine learning, and utilize the idle time of the system to build the latest microblog list for them in advance.
6. Postscript
The interviewer listened to my analysis, thinking that this kid is thinking quite comprehensively, but the face can not show it. So he nodded slightly and said, “That’s all the questions I have, so is there anything you want to ask?”
So with the idea of hijacking the interview, after asking a few painless business questions, the interview was over. After all, the interviewer is going to catch me asking about the details of the architectural design, and I may never remember it again.
I’m not sure if I’m going to be able to remember the details of the architectural design.
I not only sigh this eight-legged text, architecture questions, ** memorize is really slow, forget is really fast ** ah!
Fortunately, usually have the habit of summarizing the architectural design, not to make a fool of myself, and then will also put all the architectural design encountered during the interview process on the inside of the personal GZH, those who need to move to take their own Ha~!